
Một bài báo của Apple đã làm mất lòng cộng đồng mô hình lớn! “Dẫm lên” OpenAI và Meta để vươn lên, Gary Marcus: Đã từ lâu tôi nói mô hình lớn không thể suy luận!

Trong lĩnh vực trí tuệ nhân tạo (AI), việc cải tiến và phát triển các mô hình ngôn ngữ lớn (LLM) luôn là một chủ đề sôi nổi. Mới đây, một nhóm nghiên cứu từ Apple, bao gồm Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio và Mehrdad Farajtabar, đã công bố một bài báo quan trọng về khả năng suy luận của các mô hình ngôn ngữ. Bài báo này đã gây ra nhiều tranh cãi trong cộng đồng AI do những kết luận mà họ đưa ra.
Nhóm nghiên cứu của Apple đã kiểm tra một loạt các mô hình ngôn ngữ hàng đầu, bao gồm cả những mô hình từ OpenAI và Meta, nhằm đánh giá khả năng xử lý suy luận toán học của chúng. Kết quả cho thấy, sự thay đổi nhỏ trong cách diễn đạt câu hỏi có thể dẫn đến sự khác biệt đáng kể trong hiệu suất của các mô hình này. Điều này chỉ ra rằng các mô hình không dựa trên suy luận logic thực sự mà chỉ dựa vào việc nhận dạng mẫu từ dữ liệu huấn luyện.
Một ví dụ cụ thể được đưa ra trong bài báo: khi một câu hỏi liên quan đến việc đếm số lượng quả kiwi được thêm vào các chi tiết không liên quan, các mô hình như o1 của OpenAI và Llama của Meta đã đưa ra kết quả không chính xác. Điều này cho thấy sự phụ thuộc của các mô hình vào việc nhận dạng mẫu hơn là suy luận logic thực sự.
Nhóm nghiên cứu của Apple đã đề xuất rằng AI có thể cần kết hợp mạng nơ-ron với suy luận dựa trên ký hiệu (neuro-symbolic AI) để cải thiện khả năng ra quyết định và giải quyết vấn đề. Họ cũng giới thiệu một chuẩn mực mới để đánh giá hiệu suất của các mô hình, gọi là GSM-Symbolic, nhằm kiểm soát quá trình đánh giá.
Tuy nhiên, bài báo này cũng vấp phải nhiều chỉ trích. Một số người cho rằng nhóm nghiên cứu đã không giải thích rõ ràng về khái niệm “suy luận thực sự”, và việc đưa ra chuẩn mực mới có thể bị hiểu là cách để quảng bá cho các mô hình của riêng họ. Một số người khác lại tin rằng bài báo vẫn có giá trị nhất định vì nó tập trung vào việc đánh giá độ tin cậy của các mô hình AI, mặc dù cách tiếp cận của họ có thể chưa hoàn toàn thuyết phục.

Gary Marcus, một nhà khoa học nhận thức nổi tiếng và nhà nghiên cứu AI, cũng đã bình luận về bài báo này. Ông chỉ ra rằng các ví dụ về thất bại trong suy luận do thông tin nhiễu đã tồn tại từ lâu. Các nghiên cứu trước đó, như nghiên cứu của Robin Jia Percy Liang vào năm 2017, đã đưa ra kết quả tương tự.
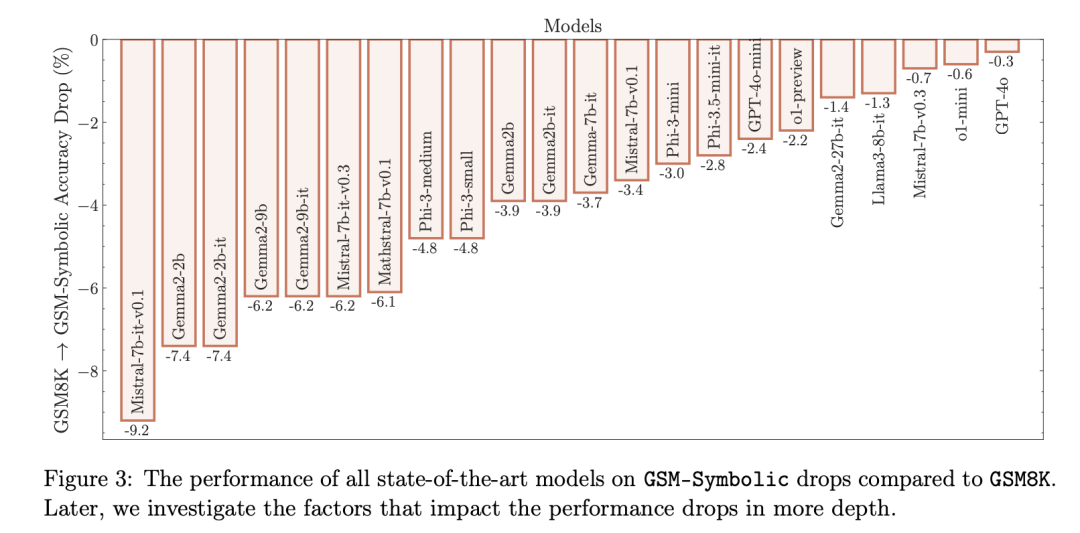
Các nghiên cứu khác cũng cho thấy rằng hiệu suất của các mô hình AI thường giảm khi kích thước của bài toán tăng lên. Điều này đặc biệt rõ ràng trong các bài toán tính toán số học, cho thấy rằng các mô hình hiện tại vẫn gặp khó khăn trong việc thực hiện suy luận dạng biểu thức.

Tóm lại, bài báo của nhóm nghiên cứu Apple đã đặt ra những câu hỏi quan trọng về khả năng suy luận của các mô hình AI hiện đại. Mặc dù có những tranh cãi, bài báo này vẫn cung cấp một cái nhìn sâu sắc về những thách thức mà ngành AI đang đối mặt và gợi ý về hướng đi tiềm năng cho tương lai.
### Từ khóa:
– Trí tuệ nhân tạo
– Mô hình ngôn ngữ lớn
– Suy luận logic
– Neuro-symbolic AI
– Hiệu suất mô hình
© Thông báo bản quyền
Bản quyền bài viết thuộc về tác giả, vui lòng không sao chép khi chưa được phép.
Những bài viết liên quan:




Không có đánh giá...