
Nhân viên 28 năm của Intel phẫn nộ tố cáo: Văn hóa công ty tồi tệ! Số lượng nhân viên gấp 5 lần đối thủ nhưng giá trị thị trường lại không bằng 5% của họ, sao lại như vậy?
Giới thiệu về mô hình AI mới Yi-Lightning
Mô hình AI mới Yi-Lightning của Zero One Wanh Wu: Tốc độ và Hiệu suất Tăng Cường

Vào ngày 16 tháng 10, sau khi công bố mô hình có 100 tỷ tham số Yi-Large vào nửa đầu năm, Zero One Wanh Wu đã chính thức ra mắt mô hình cờ hiệu mới Yi-Lightning. So với Yi-Large, Yi-Lightning không chỉ cải thiện về hiệu suất mà còn tăng tốc đáng kể trong quá trình suy luận.
Theo dữ liệu đánh giá nội bộ của Zero One Wanh Wu, trên nền tảng tính toán 8xH100, với cùng quy mô nhiệm vụ, thời gian đầu tiên của Yi-Lightning (thời gian từ lúc nhận yêu cầu đến khi hệ thống bắt đầu phản hồi) chỉ bằng một nửa so với Yi-Large. Tốc độ tạo ra kết quả cũng tăng gần 40%, thể hiện sự nâng cấp đáng kể về hiệu suất của mô hình cờ hiệu.
Ngoài ra, mô hình bên ngoài, Zero One Wanh Wu đã chọn so sánh Yi-Lightning với GPT-4o:
Theo Zero One Wanh Wu, sự cải thiện về tốc độ suy luận của Yi-Lightning có được nhờ vào khả năng AI Infra của chính nó và việc sử dụng kiến trúc Mixture of Experts (MoE). Trong quá trình huấn luyện, Yi-Lightning đã thử nghiệm nhiều phương pháp mới.
Kiểu mô hình MoE bao gồm nhiều mạng chuyên gia (Experts), cho phép mô hình này động lựa chọn kích hoạt các mạng chuyên gia phù hợp dựa trên độ khó của tác vụ. Việc này giúp cân nhắc giữa chi phí suy luận và hiệu suất của mô hình, đảm bảo rằng mô hình có thể xử lý các tác vụ khác nhau một cách hiệu quả và chính xác. Trong quá trình huấn luyện, tất cả các mạng chuyên gia đều được kích hoạt để mô hình học hỏi từ tất cả các chuyên gia; trong giai đoạn suy luận, mô hình sẽ chỉ kích hoạt các mạng chuyên gia phù hợp với tác vụ.
Các khái niệm quan trọng trong mô hình MoE là kích thước tham số được kích hoạt và tổng kích thước tham số của mô hình. Thông thường, tỷ lệ giữa kích thước tham số được kích hoạt và tổng kích thước tham số càng lớn thì mô hình càng trở nên thưa mỏng. Mặc dù việc tăng độ thưa mỏng này sẽ giảm đáng kể chi phí huấn luyện và suy luận, nhưng cũng làm giảm hiệu suất của mô hình và tăng độ khó trong huấn luyện. Do đó, mục tiêu chính trong quá trình huấn luyện mô hình MoE là duy trì hiệu suất của mô hình ở mức tối ưu trong khi giảm thiểu kích thước tham số được kích hoạt để giảm chi phí huấn luyện và tăng tốc độ suy luận.
Trong quá trình huấn luyện Yi-Lightning, đội ngũ mô hình của Zero One Wanh Wu đã thực hiện một số thử nghiệm và đạt được phản hồi tích cực:
Mechanism lai ghép (Hybrid Attention): Khác với Mistral AI sử dụng cơ chế chú ý cửa trượt (Sliding Window Attention), Zero One Wanh Wu áp dụng cơ chế lai ghép chú ý (Hybrid Attention), chỉ thay thế chú ý toàn phần (Full Attention) bằng chú ý cửa trượt (Sliding Window Attention) trong một số lớp của mô hình, nhằm cân bằng hiệu suất và tiêu thụ tài nguyên tính toán khi xử lý dữ liệu chuỗi dài. Ngoài ra, Zero One Wanh Wu còn giới thiệu thiết kế chú ý liên lớp (Cross-Layer Attention, CLA), cho phép mô hình chia sẻ khóa (Key) và giá trị (Value) giữa các lớp khác nhau, giảm nhu cầu lưu trữ. Bằng cách áp dụng chú ý liên lớp, Yi-Lightning có thể chia sẻ thông tin hiệu quả hơn giữa các lớp, cải thiện hiệu suất suy luận. Theo thông tin, việc kết hợp hai kỹ thuật này giúp Yi-Lightning giảm kích thước bộ đệm KV lên 2 đến 4 lần và giảm độ phức tạp tính toán ở một số lớp từ bậc bình phương xuống bậc tuyến tính.
Chọn lọc động Top-P: Chọn lọc động Top-P đóng vai trò như người quản lý trong mô hình MoE, tự động chọn tổ hợp mạng chuyên gia phù hợp nhất dựa trên độ khó của tác vụ mà không cần can thiệp thủ công. So với cơ chế chọn lọc truyền thống Top-K, chọn lọc động Top-P linh hoạt hơn trong việc điều chỉnh số lượng mạng chuyên gia được kích hoạt dựa trên độ khó của tác vụ, giúp cân bằng hiệu suất và chi phí suy luận tốt hơn. Sự ra đời của cơ chế chọn lọc động Top-P cũng là một trong những lý do chính khiến Yi-Lightning có thể suy luận nhanh chóng.
Đào tạo đa giai đoạn (Multi-stage Training): Trong kế hoạch đào tạo của Yi-Lightning, Zero One Wanh Wu đã cải tiến quy trình đào tạo một giai đoạn, chuyển sang quy trình đào tạo đa giai đoạn. Giai đoạn đầu tiên, đội ngũ mô hình tập trung vào đa dạng dữ liệu, giúp mô hình hấp thụ càng nhiều kiến thức khác nhau càng tốt; trong giai đoạn cuối cùng, họ tập trung vào dữ liệu phong phú và chứa nhiều kiến thức hơn. Bằng cách này, Yi-Lightning có thể hấp thụ kiến thức khác nhau ở từng giai đoạn, đồng thời điều chỉnh dữ liệu và cài đặt đào tạo để đảm bảo tốc độ và ổn định. Khi có thêm dữ liệu mới hoặc muốn đào tạo mô hình theo cách chuyên biệt, Zero One Wanh Wu có thể nhanh chóng và tiết kiệm chi phí đào tạo lại dựa trên Yi-Lightning.
Trên bảng xếp hạng đánh giá quốc tế LMSYS, Yi-Lightning vượt qua GPT-4o-2024-05-13, Claude 3.5 Sonnet, đứng thứ sáu trên thế giới và đứng đầu tại Trung Quốc.
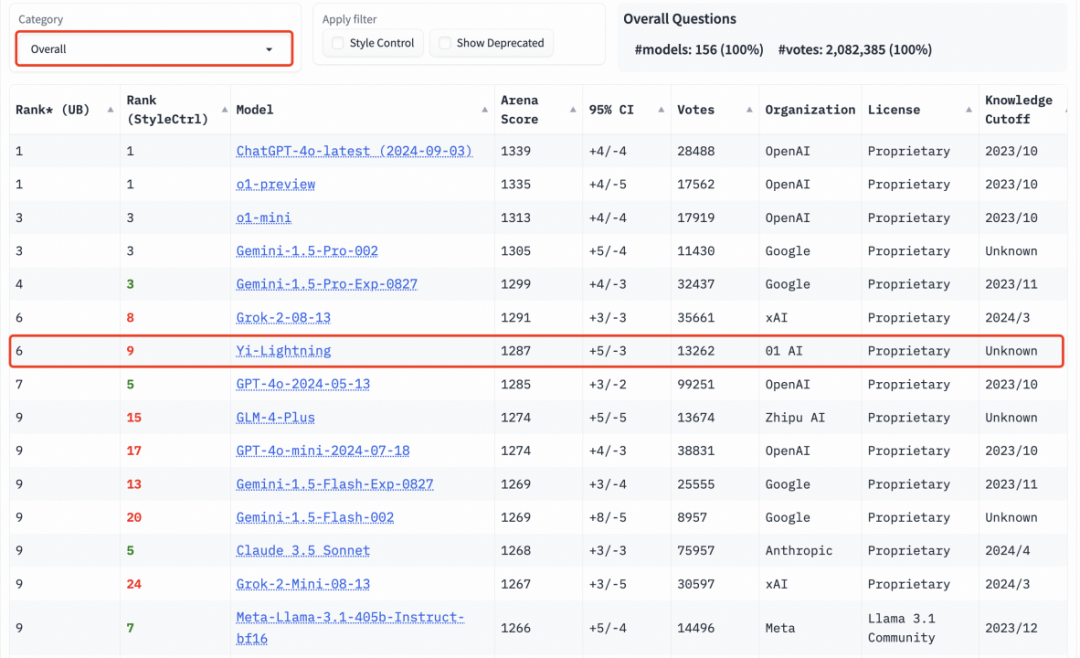
Hiện tại, Yi-Lightning đã được triển khai trên nền tảng mô hình lớn Yi (https://platform.lingyiwanwu.com/), với giá chỉ 0,99 nhân dân tệ cho mỗi triệu token, gần như giá thấp nhất trong ngành.
Li Ka-fu khẳng định rằng Zero One Wanh Wu không bị lỗ trong việc định giá Yi-Lightning. “Zero One Wanh Wu cũng đang phát triển ứng dụng di động, chúng tôi biết rằng phát triển ứng dụng di động cần kiểm soát chi phí, vì vậy chúng tôi sẽ không bán mô hình với giá lỗ, nhưng cũng không kiếm được nhiều tiền, mà chỉ thêm một chút lợi nhuận nhỏ vào chi phí, để có được giá 0,99 nhân dân tệ cho mỗi triệu token hôm nay,” ông nói.
Li Ka-fu nhấn mạnh, “Từ ngày thành lập, Zero One Wanh Wu đã đồng thời khởi động ba nhóm nghiên cứu: huấn luyện mô hình, hạ tầng AI và ứng dụng AI. Khi ba nhóm này đều trưởng thành, chúng tôi sẽ kết nối chúng lại với nhau. Zero One Wanh Wu gọi mô hình này là chiến lược xây dựng hạ tầng và ứng dụng AI cùng nhau — hạ tầng AI giúp huấn luyện và suy luận mô hình, huấn luyện mô hình với chi phí thấp hơn và hỗ trợ ứng dụng với chi phí suy luận thấp hơn.”
Tại buổi ra mắt, Li Ka-fu cũng trả lời lại thông tin trước đó về việc có tin đồn rằng các công ty mô hình lớn sẽ bỏ qua quá trình huấn luyện trước:
Theo tôi được biết, sáu công ty này đều có đủ vốn đầu tư, chúng tôi thực hiện chạy sản xuất huấn luyện một lần với chi phí từ ba đến bốn triệu đô la Mỹ, số tiền này các công ty hàng đầu đều có thể trả, tôi nghĩ rằng sáu công ty mô hình lớn ở Trung Quốc chỉ cần có đủ nhân tài tốt, quyết tâm thực hiện huấn luyện trước, vốn đầu tư và chip không phải là vấn đề.
Ngoài ra, Zero One Wanh Wu cũng công bố sản phẩm ứng dụng ngành đầu tiên dưới chiến lược ToB mới, AI 2.0 Digital Person, tập trung vào các lĩnh vực bán lẻ và thương mại điện tử, thực hành mô hình cờ hiệu mới Yi Lightning trong các giải pháp ngành cụ thể.
Dựa trên mô hình Yi Lightning đại diện cho mô hình Yi, Zero One Wanh Wu đã xây dựng nền tảng bao gồm mô hình đại diện, mô hình âm thanh trực tiếp và mô hình thoại điện tử, tạo nên nền tảng mô hình chuyên dụng hoàn chỉnh, khác biệt hoàn toàn so với giải pháp số hóa con người trong kỷ nguyên AI 1.0. Mô hình đại diện của Zero One Wanh Wu cung cấp cho AI 2.0 Digital Person khả năng huấn luyện cử chỉ và tạo biểu cảm; mô hình âm thanh trực tiếp giúp số hóa con người vượt qua rào cản ngôn ngữ và biểu cảm cảm xúc; mô hình thoại điện tử trở thành “AI Brain” của con người số, chịu trách nhiệm kết nối kho kiến thức, hoàn thành cuộc trò chuyện thông minh.
Zero One Wanh Wu cho biết, AI 2.0 Digital Person được trang bị “AI Brain” – với sự hỗ trợ của mô hình thoại điện tử, số hóa con người có thể tạo ra lời thoại trực tiếp dựa trên cơ sở dữ liệu riêng của mô hình và cơ sở dữ liệu ngoại vi, cũng có thể nhận biết chính xác và nhanh chóng ý định tương tác từ luồng bình luận trực tiếp, đưa ra câu trả lời tương ứng.
Sau khi tích hợp mô hình Yi-Lightning, AI 2.0 Digital Person của Zero One Wanh Wu có thể nhận biết chính xác hơn ý định của luồng bình luận, tạo ra lời thoại tự nhiên hơn và hoàn thành việc thúc đẩy đơn hàng ngay lập tức. Với sự sâu sắc hơn trong quá trình hợp tác với khách hàng, dựa trên khả năng gọi hàm mạnh mẽ của mô hình, AI 2.0 Digital Person của Zero One Wanh Wu có thể tương tác trơn tru với hệ thống tiếp thị và logistics hiện có của khách hàng, thực hiện việc chăm sóc khách hàng từ thu hút đến đặt hàng.
Theo thông tin, giải pháp số hóa con người AI 2.0 của Zero One Wanh Wu bao gồm các ứng dụng như bạn đồng hành AI, hình ảnh IP, trực tiếp điện tử và hội nghị văn phòng, với các trường hợp hợp tác bao gồm chuỗi đồ ăn nổi tiếng toàn quốc, khách hàng hàng đầu trong ngành rượu và du lịch, và chuỗi trái cây nổi tiếng toàn quốc, đều đạt được sự tăng trưởng đáng kể về doanh số bán hàng (GMV). Trong đó, một khách hàng hàng đầu trong ngành rượu và du lịch đã đạt được tăng trưởng 170% doanh số bán hàng sau khi tiếp cận số hóa con người trực tiếp được tăng cường bởi Yi-Lightning.
“Loại công việc này chỉ có thể được thực hiện ở Trung Quốc, vì rất khó tiếp cận người dùng Mỹ hoặc người dùng nước ngoài khác, do đó, nhà cung cấp ToB trên toàn thế giới cơ bản đều là địa phương, thậm chí ở Trung Quốc, SAP cũng bán sản phẩm cho bạn thông qua SAP Trung Quốc, do đó việc thành lập chi nhánh nước ngoài để làm ToB chắc chắn không phải là điều chúng tôi hoặc bất kỳ công ty khởi nghiệp nào khác có thể làm, do đó chúng tôi từ bỏ ToB ở nước ngoài, làm ToB ở trong nước, làm ToB với các giải pháp có lợi nhuận, không chỉ bán mô hình, không chỉ làm dự án theo kiểu dự án, đây là cách chúng tôi làm ToB,” Li Ka-fu nhấn mạnh.
Về mặt định hướng ToC, Zero One Wanh Wu chủ yếu tập trung ở nước ngoài. Đầu tiên, khi đội ngũ bắt đầu xây dựng Zero One Wanh Wu, chưa có mô hình tiếng Trung phù hợp ở Trung Quốc, chỉ có thể thử nghiệm ở nước ngoài trước, sau một thời gian thử nghiệm, họ đã rút ra được kinh nghiệm, cải tiến và tạo ra một số sản phẩm tốt. Thứ hai, môi trường phát triển sản phẩm ToC ở Trung Quốc gặp nhiều thách thức, chi phí lưu lượng ngày càng tăng nhưng người dùng vẫn có khả năng mất đi, do đó phải rất thận trọng. “Nguyên nhân lớn nhất hiện tại vẫn là phát triển sản phẩm ToC ở nước ngoài, chúng tôi có thể tính toán được khả năng thu nhập và chi phí tăng trưởng người dùng, sau này sẽ xem xét xem có cơ hội gì ở trong nước để tung ra sản phẩm,” Li Ka-fu nhấn mạnh.
Vào ngày 18-19 tháng 10, Hội nghị Phát triển và Ứng dụng Toàn cầu về Trí tuệ Nhân tạo AICon sẽ được tổ chức tại Thượng Hải. Sự kiện này sẽ tập hợp hơn 60 chuyên gia hàng đầu trong ngành trí tuệ nhân tạo, phân tích toàn diện về cơ chế huấn luyện và suy luận của mô hình lớn, sự tích hợp đa chế độ, tiến bộ tiên tiến về đại diện thông minh (Agent), chiến lược tạo ra chiến lược tăng cường tìm kiếm (RAG) và tối ưu hóa và ứng dụng mô hình bên cạnh thiết bị (Edge). Sau sự cho phép của diễn giả, “AI Frontline” sẽ cung cấp độc quyền bộ sưu tập bài thuyết trình PPT, không thể bỏ qua. Hãy theo dõi “AI Frontline”, phản hồi từ khóa “PPT” để nhận miễn phí.
**Từ khóa:**
– Trí tuệ nhân tạo
– Mô hình lớn
– Zero One Wanh Wu
– Yi-Lightning
– Suất phát điểm
© Thông báo bản quyền
Bản quyền bài viết thuộc về tác giả, vui lòng không sao chép khi chưa được phép.
Những bài viết liên quan:




Không có đánh giá...