
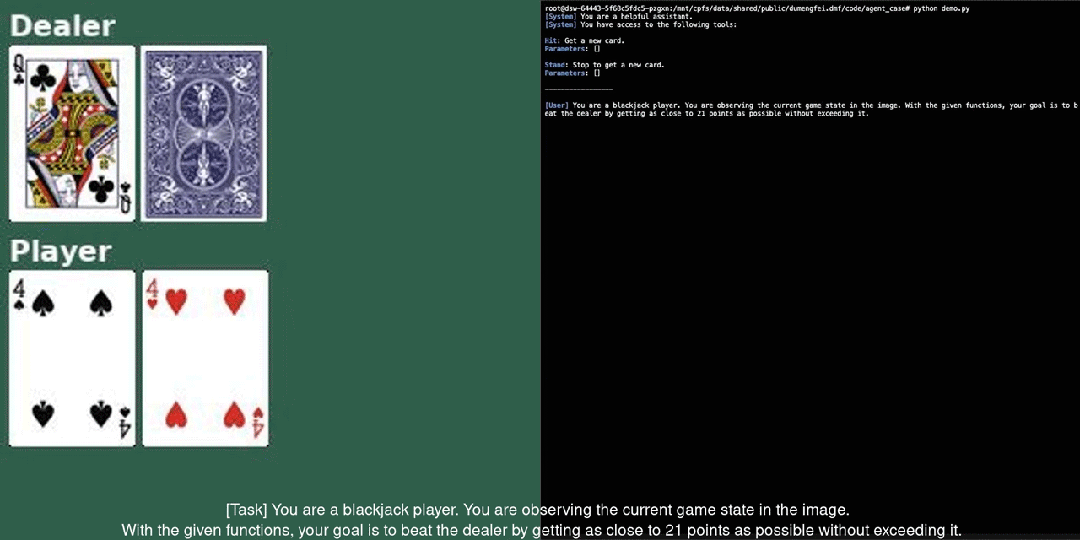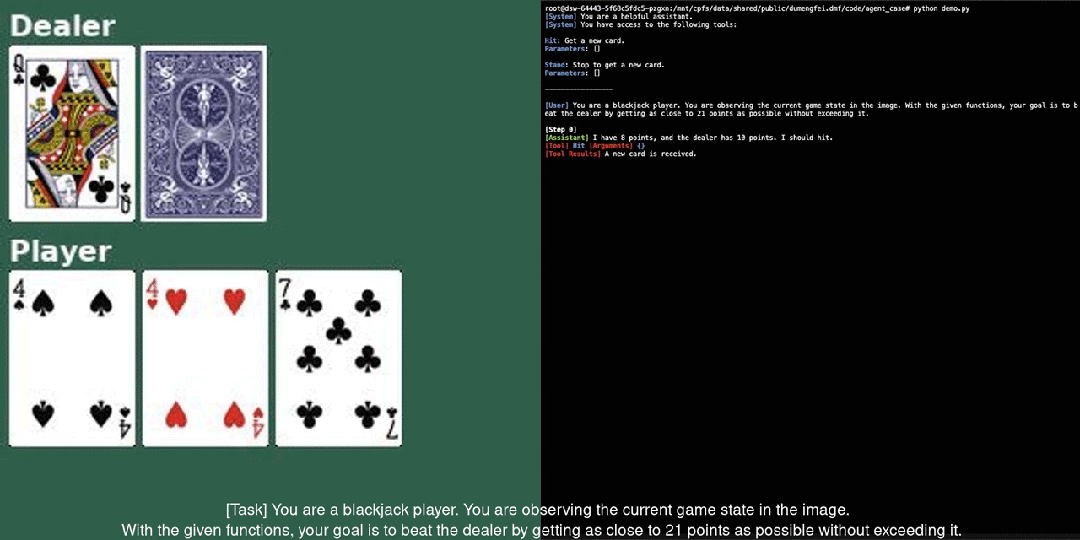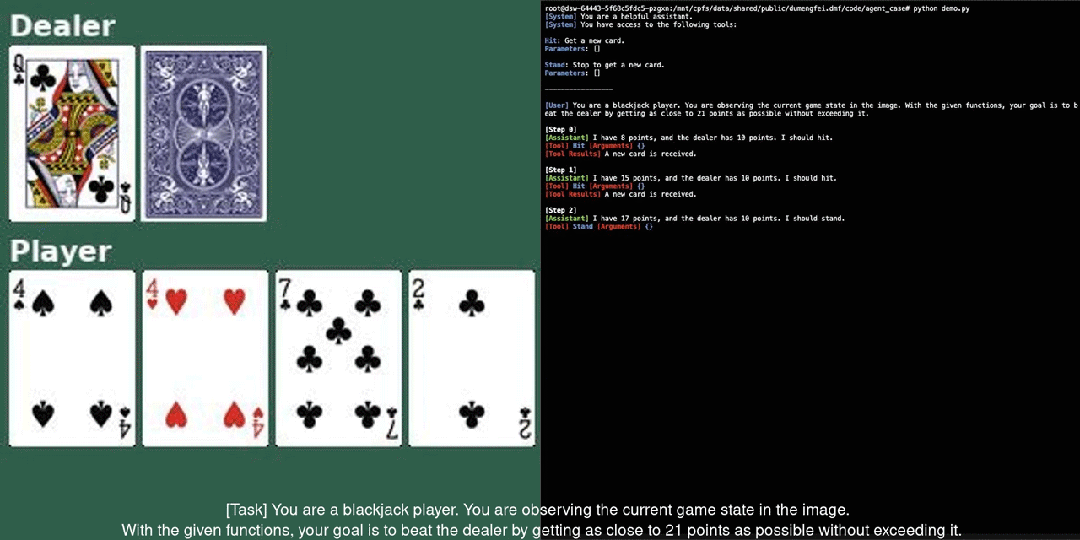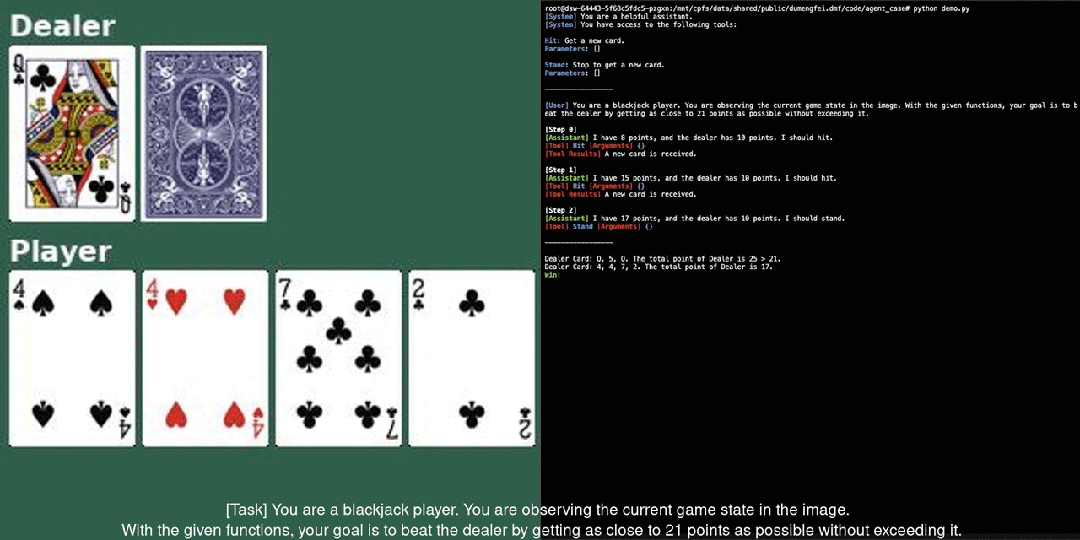
Mô hình ngôn ngữ hình ảnh mã nguồn mở Qwen2-VL, có khả năng hiểu video dài hơn 20 phút.

Trong tháng 8 năm 2023, mô hình hiểu ngữ cảnh đa phương tiện Qwen-VL của Alibaba Cloud đã trở thành một trong những mô hình đa phương tiện được yêu thích nhất trong cộng đồng mã nguồn mở. Trong vòng chưa đầy một năm, số lần tải xuống của mô hình này đã vượt quá 10 triệu lần. Hiện nay, việc áp dụng mô hình đa phương tiện trong các ứng dụng nhận dạng thị giác trên điện thoại di động và xe hơi đang diễn ra nhanh chóng, và các nhà phát triển cũng như doanh nghiệp ứng dụng đặc biệt quan tâm đến việc cải tiến và nâng cấp Qwen-VL.
So với phiên bản trước, Qwen2-VL có hiệu suất cơ bản được cải thiện đáng kể, có khả năng đọc hiểu các bức ảnh với độ phân giải khác nhau và tỷ lệ chiều khác nhau. Trên các bài kiểm tra chuẩn như DocVQA, RealWorldQA, MTVQA, mô hình này đã đạt được kết quả hàng đầu thế giới. Qwen2-VL còn có khả năng hiểu và phân tích video kéo dài hơn 20 phút, hỗ trợ ứng dụng như trả lời câu hỏi dựa trên video, đối thoại và tạo nội dung dựa trên video. Nó sở hữu khả năng thông minh thị giác mạnh mẽ, có thể tự điều khiển điện thoại di động và robot, và thông qua khả năng suy luận và ra quyết định phức tạp, mô hình này có thể được tích hợp vào các thiết bị như điện thoại di động và robot để thực hiện tác vụ tự động dựa trên môi trường thị giác và hướng dẫn văn bản. Qwen2-VL còn có khả năng hiểu và xử lý văn bản đa ngôn ngữ trong hình ảnh và video, bao gồm tiếng Trung, tiếng Anh, hầu hết các ngôn ngữ châu Âu, tiếng Nhật, tiếng Hàn, tiếng Ả Rập và tiếng Việt.
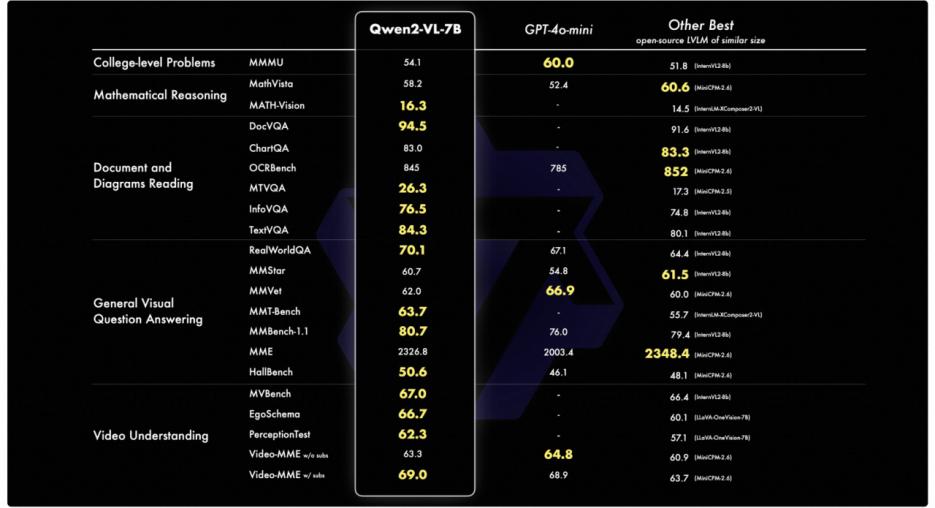
Đội ngũ Alibaba Cloud đã đánh giá mô hình Qwen2-VL từ sáu góc độ khác nhau, bao gồm cả câu hỏi đại học tổng hợp, khả năng toán học, hiểu và phân tích văn bản, bảng biểu và văn bản đa ngôn ngữ, câu hỏi về cảnh quan phổ thông, hiểu video và khả năng của Agent. Qwen2-VL-7B đã chứng tỏ hiệu suất cạnh tranh cao mặc dù có quy mô tham số “tiết kiệm”; Qwen2-VL-2B thì có thể hỗ trợ nhiều ứng dụng trên thiết bị di động, đồng thời vẫn giữ được khả năng hiểu và phân tích hình ảnh và video đa ngôn ngữ đầy đủ, với lợi thế rõ ràng so với các mô hình cùng quy mô trong việc hiểu video và câu hỏi về cảnh quan phổ thông.
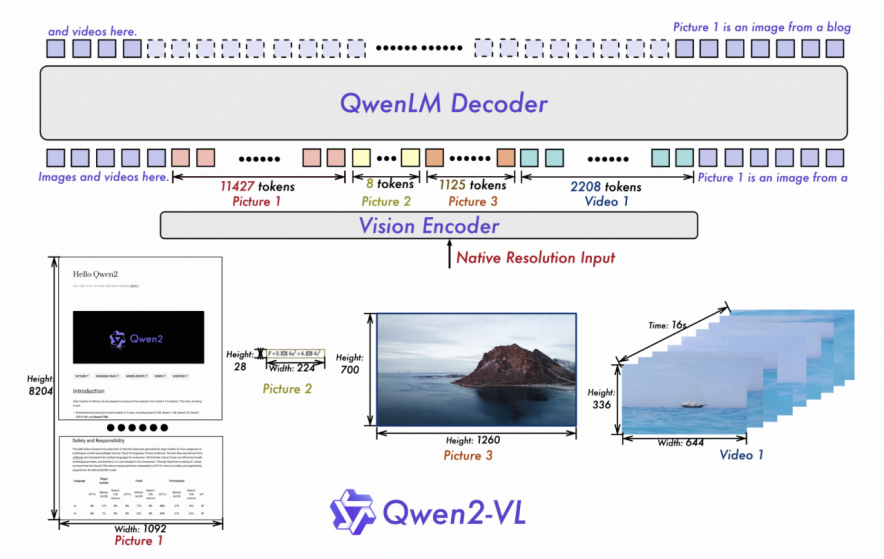
Qwen2-VL tiếp tục sử dụng cấu trúc kết nối giữa ViT và Qwen2, với tất cả ba kích thước của mô hình đều sử dụng quy mô ViT 600M. Nhóm nghiên cứu đã thực hiện hai cải tiến lớn trong kiến trúc:
1. Đạt được sự hỗ trợ toàn diện cho độ phân giải động gốc, khác biệt so với mô hình trước đó, Qwen2-VL có khả năng xử lý bất kỳ kích thước hình ảnh nào, giúp mô hình có khả năng xử lý bất kỳ kích thước hình ảnh nào, mô phỏng cách nhìn thị giác tự nhiên của con người.
2. Sử dụng phương pháp M-ROPE (Multi-modal Rotational Position Embedding), giúp mô hình có khả năng nắm bắt và tích hợp thông tin vị trí từ chuỗi văn bản một chiều, hình ảnh hai chiều và video ba chiều, tăng cường khả năng xử lý và suy luận đa phương tiện của mô hình.

Hiện tại, đội ngũ Alibaba Cloud đã mở nguồn Qwen2-VL-2B và Qwen2-VL-7B theo giấy phép Apache 2.0. Mã nguồn đã được tích hợp vào các khung làm việc như Hugging Face Transformers, vLLM và các khung bên thứ ba khác. Người dùng có thể tải và sử dụng mô hình thông qua Hugging Face và ModelScope của Alibaba Cloud, hoặc thông qua trang web chính thức của Alibaba Cloud và ứng dụng chính của nó.

Qwen2-VL tiếp tục duy trì cấu trúc kết nối ViT và Qwen2, với tất cả ba kích thước của mô hình đều sử dụng quy mô ViT 600M. Nhóm nghiên cứu đã thực hiện hai cải tiến lớn trong kiến trúc:
1. Đạt được sự hỗ trợ toàn diện cho độ phân giải động gốc, khác biệt so với mô hình trước đó, Qwen2-VL có khả năng xử lý bất kỳ kích thước hình ảnh nào, giúp mô hình có khả năng xử lý bất kỳ kích thước hình ảnh nào, mô phỏng cách nhìn thị giác tự nhiên của con người.
2. Sử dụng phương pháp M-ROPE (Multi-modal Rotational Position Embedding), giúp mô hình có khả năng nắm bắt và tích hợp thông tin vị trí từ chuỗi văn bản một chiều, hình ảnh hai chiều và video ba chiều, tăng cường khả năng xử lý và suy luận đa phương tiện của mô hình.
Hiện tại, đội ngũ Alibaba Cloud đã mở nguồn Qwen2-VL-2B và Qwen2-VL-7B theo giấy phép Apache 2.0. Mã nguồn đã được tích hợp vào các khung làm việc như Hugging Face Transformers, vLLM và các khung bên thứ ba khác. Người dùng có thể tải và sử dụng mô hình thông qua Hugging Face và ModelScope của Alibaba Cloud, hoặc thông qua trang web chính thức của Alibaba Cloud và ứng dụng chính của nó.
### Từ khóa
– Qwen2-VL
– Alibaba Cloud
– M-ROPE
– Apache 2.0
– AI
© Thông báo bản quyền
Bản quyền bài viết thuộc về tác giả, vui lòng không sao chép khi chưa được phép.
Những bài viết liên quan:




Không có đánh giá...