
Chúng tôi đã hoàn thành tinh chỉnh Open-Sora trong 1000 giờ GPU như thế nào.
Khám phá Quá trình Tạo Video từ Văn bản với Text2Video
Bạn có tò mò về cách sử dụng công nghệ tiên tiến để cải thiện chất lượng video được tạo ra? Bạn muốn biết làm thế nào để tạo ra những hiệu ứng thị giác ấn tượng thông qua việc điều chỉnh mô hình? Bài viết này sẽ dẫn bạn đi sâu vào quá trình từ cấu hình phần cứng đến chuẩn bị dữ liệu và điều chỉnh mô hình. Chúng tôi sẽ chia sẻ cách chúng tôi vượt qua các thách thức trong quá trình thực hành và không ngừng nâng cao chất lượng video được tạo ra, bao gồm cả độ phân giải và số khung hình.
Mô hình Text2Video đã mở ra một lĩnh vực sáng tạo mới cho các nhà phát triển và người tạo nội dung. Tuy nhiên, do khó khăn trong việc tiếp cận các mô hình chuyên dụng hoặc do yêu cầu cụ thể không phù hợp, những mô hình này có thể không đáp ứng mọi nhu cầu. Nhưng tin vui là, bằng cách điều chỉnh mô hình nguồn mở của riêng bạn, bạn có thể tăng đáng kể khả năng tạo video phù hợp với dự án của mình, từ việc tạo phong cách nghệ thuật độc đáo đến cải thiện chất lượng hình ảnh của chủ đề cụ thể. Ví dụ, bạn có thể tái hiện lại cảnh quay kinh điển từ một bộ phim theo một phong cách nghệ thuật đặc biệt.
Tiếp theo, bài viết này sẽ hướng dẫn chi tiết cách điều chỉnh mô hình Open-Sora 1.1 Stage3 để tạo ra video định dạng stop-motion. Chúng tôi đã công bố hai mô hình để bạn lựa chọn:
- lambdalabs/text2bricks-360p-64f: Mô hình này đã được huấn luyện trong 1000 giờ GPU (dựa trên NVIDIA H100) và có khả năng tạo ra video 360p với tối đa 64 khung hình.
- lambdalabs/text2bricks-360p-32f: Mô hình này đã được huấn luyện trong 170 giờ GPU (dựa trên NVIDIA H100) và có khả năng tạo ra video 360p với tối đa 32 khung hình.
Để giúp bạn dễ dàng sử dụng, chúng tôi đã công bố mã nguồn (đây là nhánh sửa đổi của chúng tôi dựa trên Open-Sora), tập dữ liệu và mô hình (bao gồm cả 32f và 64f). Ngoài ra, bạn cũng có thể thử nghiệm mô hình 64f thông qua trình demo Gradio để cảm nhận hiệu quả bất ngờ mà nó mang lại.
Dưới đây là một số ví dụ về đầu ra để bạn tham khảo:
Sau khi điều chỉnh mô hình cẩn thận, chúng tôi đã tạo ra video động với các khối gạch như sau:

Khi phi hành gia đi bộ trên mặt trăng, do trọng lực yếu hơn, bước chân của họ thể hiện một sự nhẹ nhàng và đàn hồi đặc trưng, như thể mỗi bước chân đều nhảy lên nhẹ nhàng.

Trên những con phố hẹp ở Rome, mọi người đang thưởng thức kem ngon tại các quán cà phê ngoài trời, đồng thời nhâm nhi cà phê espresso. Hai bên đường, các cửa hàng bày bán đủ loại hàng hóa, từ trái cây tươi đến rau củ và đồ trang trí Giáng sinh đầy màu sắc, mang lại không khí ấm áp và vui vẻ cho mùa lễ hội sắp tới.
Cấu hình Phần Cứng
Hệ thống huấn luyện của chúng tôi là một cụm 32-GPU do Lambda cung cấp, được thiết lập chỉ với một cú nhấp chuột. Cụm này bao gồm bốn máy chủ NVIDIA HGX H100, mỗi máy chủ có 8 card NVIDIA H100 SXM Tensor Core GPU và được kết nối thông qua mạng NVIDIA Quantum-2 400 Gb/s InfiniBand. Tốc độ băng thông giữa các nút đạt 3200 Gb/s, đảm bảo khả năng mở rộng phân tán hiệu quả trên nhiều nút. Ngoài ra, cụm còn được trang bị hệ thống lưu trữ file chia sẻ theo yêu cầu của Lambda Cloud, cho phép dữ liệu, mã và môi trường Python được chia sẻ một cách liền mạch trên tất cả các nút. Để tìm hiểu thêm về cụm một cú nhấp chuột, hãy xem bài viết này.
Cấu hình Phần Mềm
Cụm 32-GPU của chúng tôi đã được cài đặt sẵn các trình điều khiển NVIDIA. Để đơn giản hóa việc cấu hình môi trường, chúng tôi đã viết một hướng dẫn để hướng dẫn người dùng cách tạo môi trường Conda để quản lý các phụ thuộc của Open-Sora, bao gồm NVIDIA CUDA, NVIDIA NCCL, PyTorch, Transformers, Diffusers, Flash-Attention và NVIDIA Apex. Để kích hoạt môi trường Conda trên tất cả các nút, chúng tôi đã đặt môi trường này vào hệ thống lưu trữ file chia sẻ.
Với cụm 32-GPU này, chúng tôi có thể huấn luyện lên đến 97.200 đoạn video mỗi giờ (mỗi đoạn video có độ phân giải 360p và 32 khung hình mỗi giây).
Nguồn Dữ Liệu
Dữ liệu của chúng tôi lấy từ các kênh YouTube nổi tiếng như MICHAELHICKOXFilms, LEGO Land, FK Films và LEGOSTOP Films. Các video này đều là các tác phẩm hoạt hình stop-motion chất lượng cao sử dụng các khối LEGO®. Tập dữ liệu đầy đủ có thể tải về từ Hugging Face: [Liên kết đến tập dữ liệu đầy đủ].
Để giúp người dùng tạo dữ liệu tùy chỉnh từ URL YouTube, chúng tôi cung cấp một script. Quy trình xử lý dữ liệu tuân theo nguyên tắc hướng dẫn của Open-Sora, bắt đầu bằng việc cắt video thành các đoạn từ 15 đến 200 khung hình, sau đó sử dụng mô hình ngôn ngữ thị giác để đánh dấu các đoạn này. Tập dữ liệu của chúng tôi chứa 24.000 đoạn video 720p/16:9. Ngoài ra, Open-Sora còn khuyến nghị bổ sung hình ảnh tĩnh để giúp mô hình học hỏi chi tiết về ngoại hình của đối tượng. Do đó, chúng tôi thu thập khung hình giữa của mỗi video để bổ sung vào tập dữ liệu.
Ghi chú Dữ Liệu
Chúng tôi đã sử dụng GPT-4o và các gợi ý cụ thể để đánh dấu các đoạn video. Dưới đây là các gợi ý của chúng tôi:
Chúng tôi đã cung cấp cho GPT-4o một số gợi ý từ các đoạn trình diễn của Sora từ OpenAI, bao gồm “một phụ nữ sành điệu tự tin dạo bước trên các con phố Tokyo”, “mamut di chuyển trên thảo nguyên tuyết”, và “Big Sur” v.v. Khung hình giữa của video cũng được mô tả bởi GPT-4o, và các gợi ý cho dữ liệu hình ảnh đã được điều chỉnh phù hợp.
Dù các mô tả này được tạo ra bởi mô hình GPT mới nhất và tiên tiến nhất, nhưng vẫn có thể có sai lệch. Dưới đây là một ví dụ, trong đó các từ in đậm là mô tả không chính xác. Điều này nhấn mạnh thách thức trong việc thu thập nhãn dữ liệu chất lượng cao trong các lĩnh vực cụ thể.

Một nhân vật ngồi với biểu cảm kinh ngạc trong một phòng tắm, sau đó biểu cảm dần dần chuyển sang thư giãn và hài lòng. Bên cạnh nhân vật là một tủ màu nâu và bồn rửa màu trắng. Sàn nhà từ màu xanh chuyển dần sang màu xanh lá cây, và còn có một vật giống như túi xách. Toàn bộ cảnh tượng cho thấy một không gian nội thất đơn giản, với nhân vật trải qua sự thay đổi cảm xúc nhanh chóng.
Mô Hình Tiền Huấn Luyện
Chúng tôi đã sử dụng mô hình Open-Sora mới nhất được phát hành (ngày 25 tháng 4 năm 2024), vì nó nổi tiếng với khả năng tiếp tục huấn luyện ở các độ phân giải và tỷ lệ khung hình khác nhau. Kế hoạch của chúng tôi là sử dụng dữ liệu BrickFilm để điều chỉnh mô hình tiền huấn luyện OpenSora-STDiT-v2-stage3, nhằm tạo ra video có phong cách tương tự. Để biết thêm về cấu hình và lệnh huấn luyện mô hình, hãy xem hướng dẫn này.
Mô hình đầu tiên của chúng tôi (text2bricks-360p-64f) có khả năng tạo video 360p với tối đa 64 khung hình. Trên nền tảng H100, toàn bộ quá trình huấn luyện mất 1017.6 giờ H100, với các bước cụ thể như sau:
- Thử nghiệm ban đầu (160 giờ H100): Chúng tôi tập trung vào việc tạo video 360p với 16 khung hình. Để đảm bảo ổn định trong quá trình điều chỉnh, chúng tôi giữ tốc độ học cố định ở mức 1e-5 trước khi thực hiện 500 bước cosine warmup. Bước này giúp “khôi phục” trạng thái tối ưu hóa, tránh hiện tượng mô hình hành vi bất thường trong giai đoạn đầu.
- Điều chỉnh và mở rộng (857.6 giờ H100): Sau đó, chúng tôi bổ sung dữ liệu hình ảnh và mở rộng cấu hình để hỗ trợ 32 khung hình và 64 khung hình.
Bên cạnh đó, chúng tôi cũng đã huấn luyện một mô hình khác (text2bricks-360p-32f), mất 169.6 giờ H100 và sử dụng chiến lược lịch trình học tập đơn chu kỳ. Mô hình này cũng đạt được kết quả đáng kinh ngạc trong việc tạo video 360p với tối đa 32 khung hình. Các bước cụ thể như sau:
- Thử nghiệm ban đầu (67.84 giờ H100): Chúng tôi dần tăng tốc độ học từ 1e-7 lên 1e-4 và thực hiện 1500 bước cosine warmup.
- Điều chỉnh và mở rộng (101.76 giờ H100): Sau đó, chúng tôi giảm tốc độ học xuống 1e-5 và thực hiện 2500 bước cosine annealing.
Các bảng dưới đây minh họa quá trình tiến hóa của đầu ra mô hình trong giai đoạn điều chỉnh. Chúng tôi đã cố định hạt ngẫu nhiên để đảm bảo tính công bằng trong so sánh.




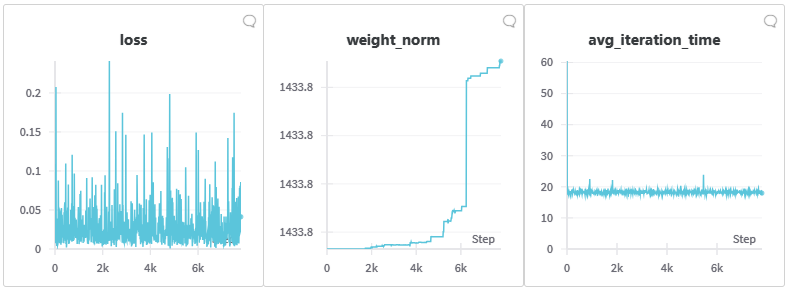
Trong quá trình điều chỉnh, chúng tôi quan sát thấy tổn thất không giảm. Tuy nhiên, đáng chú ý là từ kết quả kiểm tra, mô hình không bị sụp đổ mà chất lượng hình ảnh tạo ra ngày càng được cải thiện. Điều này cho thấy sự cải thiện hiệu suất của mô hình không nhất thiết phản ánh trực tiếp vào giá trị tổn thất.
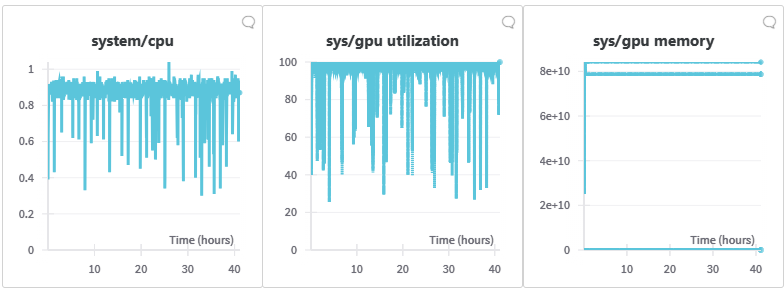
Qua bảng điều khiển giám sát của W&B, chúng tôi quan sát thấy tỷ lệ sử dụng CPU trong nhiệm vụ điều chỉnh này rất thấp, trong khi GPU liên tục bận rộn với việc xử lý dữ liệu. Mặc dù đôi khi có sự giảm nhẹ do đánh giá và tạo điểm kiểm tra, tỷ lệ sử dụng tính toán và bộ nhớ GPU luôn duy trì ở mức cao. Điều này nhấn mạnh tầm quan trọng của việc mở rộng hiệu quả trong quá trình huấn luyện mô hình cơ sở. Dịch vụ cụm một cú nhấp chuột của Lambda, với các card GPU NVIDIA H100 Tensor Core và mạng InfiniBand NVIDIA Quantum-2 400Gb/s, cung cấp sự hỗ trợ mạnh mẽ cho điều này.
Dù kết quả hiện tại rất đáng khích lệ, mô hình của chúng tôi vẫn cần cải thiện ở một số khía cạnh:
- Thời gian nhất quán trong chuỗi dài: Trong các chuỗi video dài, chúng tôi phát hiện sự nhất quán thời gian yếu. Điều này có thể liên quan đến việc ST-DiT-2 sử dụng cơ chế chú ý độc lập trên không gian và thời gian. Mặc dù điều này giảm thiểu chi phí tính toán, nhưng có thể hạn chế việc chú ý được áp dụng trong “cửa sổ ngữ cảnh cục bộ”, dẫn đến sự trôi dạt trong video được tạo ra. Việc tích hợp chú ý không gian và thời gian có thể là chìa khóa để giải quyết vấn đề này.
- Âm thanh trong quá trình tạo không điều kiện: Khi tạo video không điều kiện (thiết lập cfg=0), chúng tôi quan sát thấy sự xuất hiện của nhiễu. Điều này cho thấy mô hình vẫn cần cải thiện trong việc học biểu diễn của các video động gạch. Các giải pháp tiềm năng có thể bao gồm việc mở rộng thêm dữ liệu và khám phá cách để mô hình học hỏi biểu diễn hiệu quả hơn.
- Độ phân giải và số khung hình: Đưa kết quả ra khỏi 360p và 64 khung hình là một hướng phát triển quan trọng trong tương lai. Việc đạt được độ phân giải cao hơn và chuỗi dài hơn sẽ nâng cao khả năng thực tế và phạm vi ứng dụng của mô hình.
- Chất lượng và số lượng dữ liệu: Chất lượng và số lượng của tập dữ liệu cần được cải thiện.
Kết luận
Bài viết này đã giới thiệu quy trình từ cấu hình phần cứng đến chuẩn bị dữ liệu và điều chỉnh mô hình để tạo video từ văn bản. Chúng tôi hy vọng rằng thông qua việc chia sẻ kinh nghiệm và kiến thức của mình, bạn sẽ có cái nhìn sâu hơn về cách tận dụng công nghệ tiên tiến để tạo ra video chất lượng cao.
Từ khóa
- Video từ văn bản
- Open-Sora
- Micro-adjustment
- Video động gạch
- ST-DiT-2
© Thông báo bản quyền
Bản quyền bài viết thuộc về tác giả, vui lòng không sao chép khi chưa được phép.
Những bài viết liên quan:




Không có đánh giá...