
Triển khai CPU mô hình lớn tại đầu cuối có thể nâng cao hiệu quả lên 6 lần! Dự án mã nguồn mở mới từ Viện Nghiên cứu Microsoft đã được công bố.
T-MAC: Đột Phá Trong Triển Khai Mô Hình Ngôn Ngữ Lớn Trên Thiết Bị Biên Cạnh
Một xu hướng mới đang xuất hiện trong việc tăng cường tính năng thông minh trên thiết bị biên cạnh, đó là triển khai các mô hình ngôn ngữ lớn (LLMs). Hiện tại, nhiều mô hình này được lượng tử hóa xuống mức bit thấp. Tuy nhiên, quá trình suy luận đòi hỏi phép nhân ma trận hỗn hợp độ chính xác giữa trọng số mức bit thấp và vector kích hoạt mức bit cao (mpGEMM). Do thiếu hỗ trợ phần cứng gốc cho mpGEMM, các hệ thống hiện tại phải đảo ngược lượng tử hóa để thực hiện tính toán mức bit cao. Điều này dẫn đến một lượng đáng kể chi phí suy luận và không thể tận dụng được lợi thế của việc giảm bit thêm.
Để giải quyết vấn đề này, nhóm nghiên cứu từ Microsoft Asia Research đã phát triển T-MAC. T-MAC sử dụng mô hình tính toán dựa trên bảng tra cứu (LUT), không cần đảo ngược lượng tử hóa, hỗ trợ trực tiếp phép nhân ma trận hỗn hợp mức bit. Hiệu suất suy luận hiệu quả và khả năng mở rộng thống nhất của nó đã mở đường cho việc triển khai thực tế các mô hình mức bit thấp trên các thiết bị biên cạnh có tài nguyên hạn chế.
Hiện nay, việc triển khai các mô hình lớn chủ yếu phụ thuộc vào các bộ xử lý chuyên dụng như NPU và GPU. Tuy nhiên, T-MAC có thể hoạt động mà không cần đến các bộ xử lý chuyên dụng này, chỉ cần sử dụng CPU để triển khai mô hình LLM. Tốc độ suy luận thậm chí còn vượt trội hơn so với các bộ xử lý chuyên dụng cùng nền tảng, cho phép triển khai LLM trên nhiều loại thiết bị biên cạnh bao gồm PC, điện thoại di động, Raspberry Pi và nhiều hơn nữa. Mã nguồn của T-MAC đã được mở cửa cho cộng đồng.
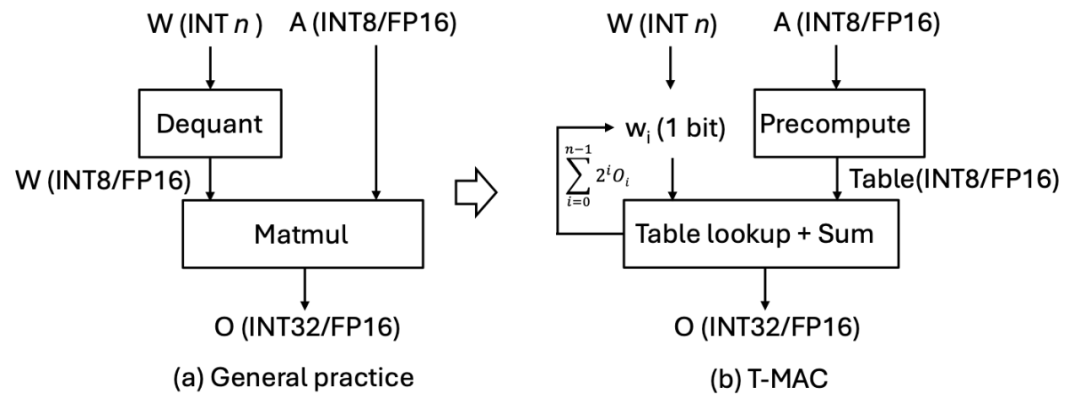
Các sáng kiến quan trọng của T-MAC nằm ở việc sử dụng mô hình tính toán dựa trên bảng tra cứu (LUT) thay vì mô hình tính toán truyền thống dựa trên phép nhân cộng dồn (MAC). Bằng cách sử dụng bảng tra cứu, T-MAC có thể trực tiếp hỗ trợ tính toán mức bit thấp, loại bỏ nhu cầu về thao tác đảo ngược lượng tử (dequantization) và giảm đáng kể số lượng phép nhân và cộng dồn.
Qua các thử nghiệm, T-MAC đã chứng minh hiệu suất vượt trội: trên Surface AI PC được trang bị bộ vi xử lý Qualcomm Snapdragon X Elite mới nhất, mô hình BitNet-b1.58 3B đạt tốc độ sinh ra 48 token mỗi giây, mô hình llama 7B 2bit đạt 30 token mỗi giây, và mô hình llama 7B 4bit đạt 20 token mỗi giây. Điều này thậm chí còn vượt qua hiệu suất của NPU!
Khi triển khai mô hình llama-2-7b-4bit, mặc dù NPU có thể tạo ra 10.4 token mỗi giây, nhưng CPU với sự hỗ trợ của T-MAC chỉ cần hai lõi để đạt được tốc độ 12.6 token mỗi giây, tối đa có thể lên tới 22 token mỗi giây. Điều này vượt xa tốc độ đọc trung bình của con người, cải thiện hiệu suất từ 4 đến 5 lần so với khung công cụ gốc llama.cpp. Ngay cả trên thiết bị thấp cấp như Raspberry Pi 5, T-MAC vẫn đạt được tốc độ sinh ra 11 token mỗi giây cho mô hình BitNet-b1.58 3B. T-MAC cũng có lợi thế về năng lượng: đạt cùng tốc độ sinh ra, T-MAC chỉ cần 1/4 đến 1/6 số lõi so với llama.cpp, giảm tiêu thụ năng lượng và để lại tài nguyên tính toán cho các ứng dụng khác.
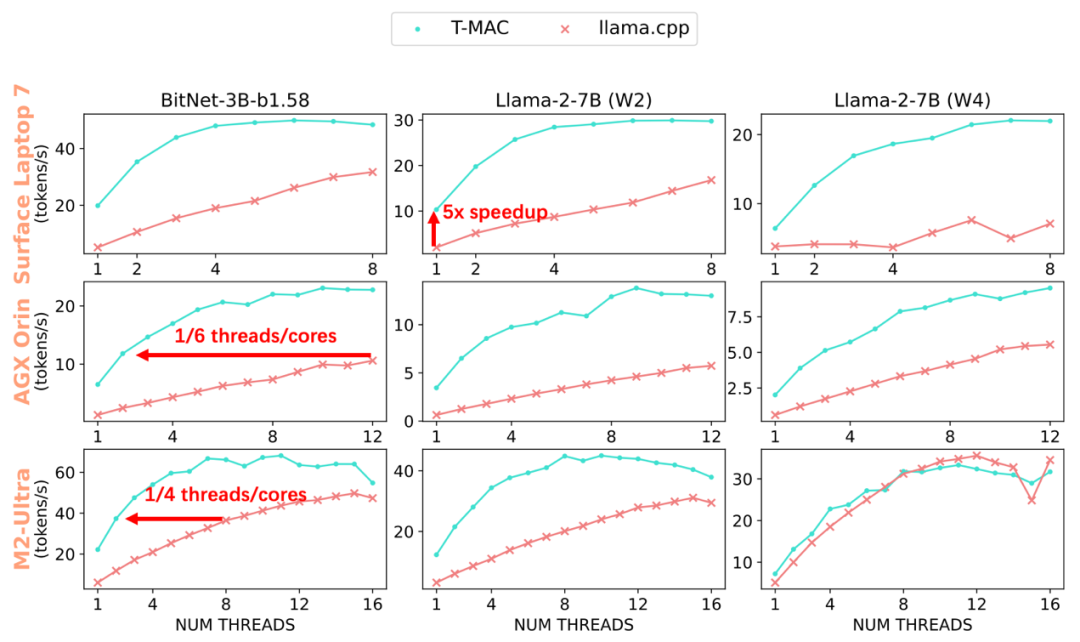
Ngoài ra, hiệu suất tính toán của T-MAC tăng tuyến tính khi giảm mức bit, điều này không dễ dàng quan sát trong các hệ thống dựa trên đảo ngược lượng tử như GPU và NPU. Tuy nhiên, T-MAC có thể đạt được tốc độ 10 token mỗi giây trên một lõi và 28 token mỗi giây trên bốn lõi, vượt xa hiệu suất của NPU.
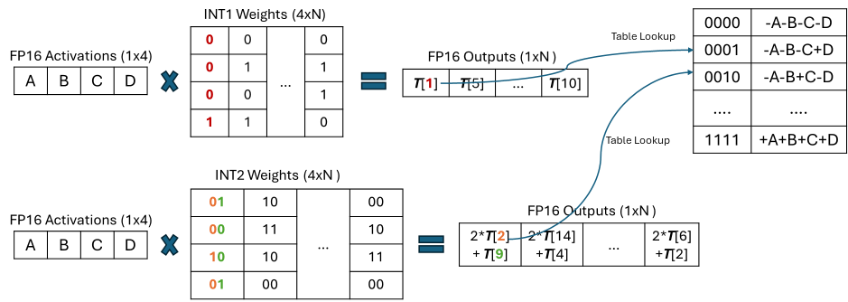
Đối với các trọng số mức bit thấp, T-MAC chia mỗi mức bit thành các nhóm riêng biệt (ví dụ: nhóm 4 mức bit), sau đó nhân chúng với vector kích hoạt, tính toán tất cả tổng phần có thể trước và lưu trữ trong bảng tra cứu. Tiếp theo, T-MAC sử dụng các thao tác dịch và cộng dồn để hỗ trợ từ 1 đến 4 mức bit có thể mở rộng. Phương pháp này loại bỏ lệnh FMA (tích cộng) không hiệu quả trên CPU và chuyển sang sử dụng lệnh TBL/PSHUF (tra cứu bảng) tiêu thụ ít năng lượng hơn và hiệu quả hơn.
Mô hình tính toán dựa trên mức bit mang lại nhiều ưu điểm, nhưng triển khai trên CPU vẫn gặp thách thức đáng kể: (i) truy cập bảng tra cứu ngẫu nhiên so với truy cập dữ liệu liên tục của vector kích hoạt và trọng số, (ii) bộ nhớ trên chip là hạn chế, và phương pháp bảng tra cứu làm tăng sử dụng bộ nhớ trên chip.
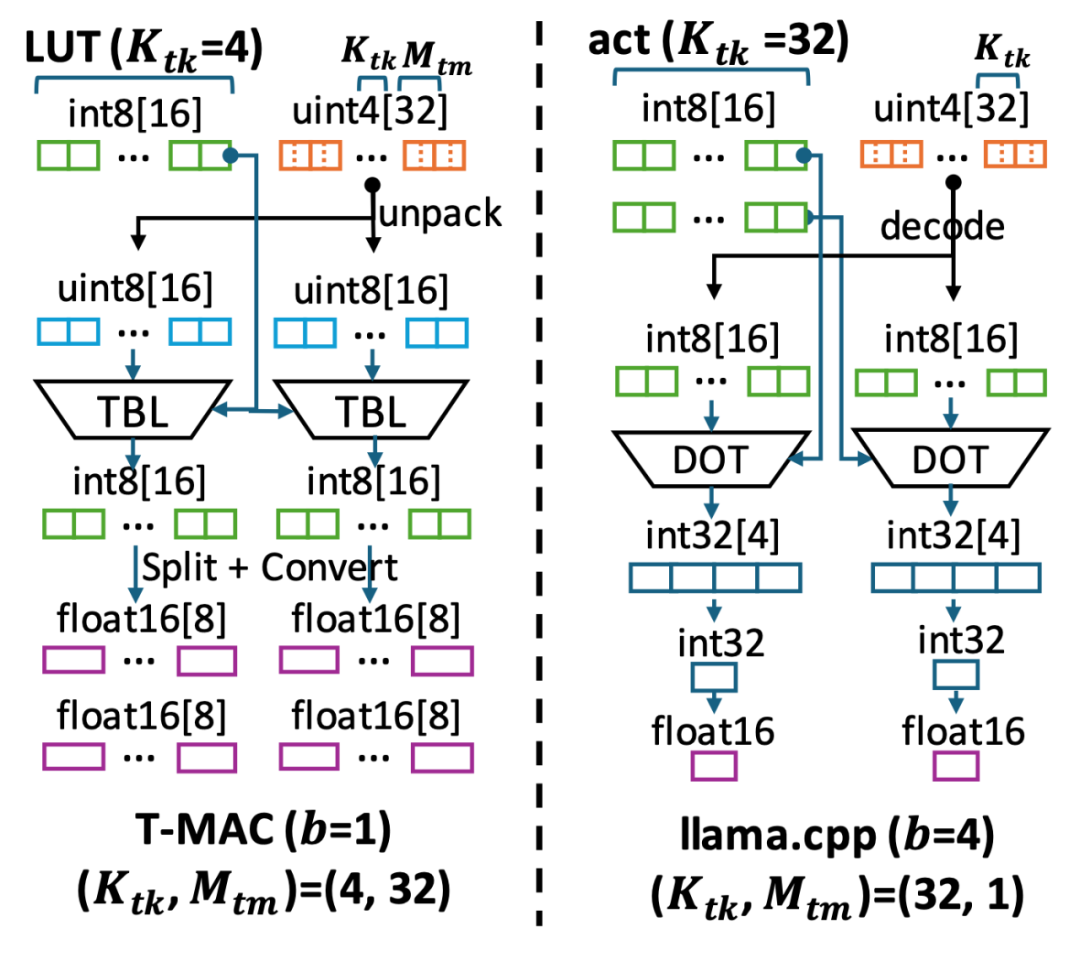
Để giải quyết những thách thức này, nhóm nghiên cứu đã khám phá quy trình dữ liệu tính toán dựa trên bảng tra cứu, thiết kế cấu trúc dữ liệu và quy trình tính toán hiệu quả:
- Lưu bảng tra cứu vào bộ nhớ trên chip để tận dụng các lệnh truy cập bảng tra cứu (TBL/PSHUF) trên CPU.
- Thay đổi thứ tự tính toán trục ma trận để tối đa hóa tái sử dụng dữ liệu trong bộ nhớ trên chip giới hạn.
- Thiết kế cách phân chia ma trận (Tiling) tối ưu cho truy cập bảng tra cứu, kết hợp tìm kiếm tham số tối ưu bằng autotvm.
- Tối ưu hóa bố trí trọng số.
- Chỉnh sửa lại trọng số để truy cập liên tục và tăng tỷ lệ trúng bộ đệm.
- Chia nhỏ trọng số để tăng hiệu quả giải mã.
- Tối ưu hóa cho CPU Intel/ARM, bao gồm:
- Sắp xếp lại đăng ký để nhanh chóng thiết lập bảng tra cứu.
- Sử dụng lệnh trung bình để cộng dồn 8-bit nhanh chóng.
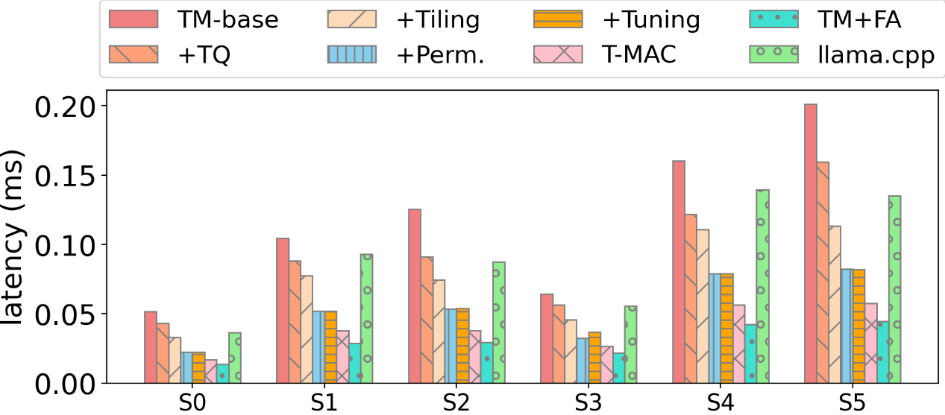
Sau khi áp dụng từng bước tối ưu trên cơ sở thực hiện ban đầu, T-MAC đã đạt được hiệu suất vượt trội so với các thuật toán mức bit thấp hàng đầu:
Mã nguồn của T-MAC đã được mở cửa tại https://github.com/microsoft/T-MAC, bạn có thể dễ dàng cài đặt và chạy mô hình Llama-3-8B-instruct trên máy tính xách tay của mình.
Mã nguồn: https://github.com/microsoft/T-MAC
Bài báo: https://www.arxiv.org/pdf/2407.00088
Ngày 18-19 tháng 8, Hội nghị Toàn cầu về Phát triển và Ứng dụng Trí tuệ Nhân tạo (AICon) sẽ diễn ra tại Thượng Hải. 60 chuyên gia hàng đầu từ các tổ chức như ByteDance, Huawei, Alibaba, Microsoft Asia Research Institute, Zhiyuan Institute of Artificial Intelligence, Shanghai AI Laboratory, NIO, Xiaohongshu và Zero One Wanwu sẽ chia sẻ các cảnh quan và thực tiễn tốt nhất về triển khai AI và mô hình lớn. Đăng ký ngay để nhận thông tin chi tiết từ đại diện vé.
Từ khóa
- T-MAC
- Mô hình Ngôn ngữ Lớn
- Hỗn hợp Độ chính xác
- Trái phiếu
- AI
© Thông báo bản quyền
Bản quyền bài viết thuộc về tác giả, vui lòng không sao chép khi chưa được phép.
Những bài viết liên quan:




Không có đánh giá...