
Huấn luyện gặp phải 419 lần sự cố bất ngờ! GPU Nvidia suýt không thể xử lý mô hình 405B, hoàn toàn nhờ vào các kỹ sư Meta cứu vớt!
Llama 3 405B: Thử thách và giải pháp trong quá trình huấn luyện
Mới đây, Meta đã công bố một báo cáo nghiên cứu về việc huấn luyện mô hình ngôn ngữ lớn Llama 3 405B, với 405 tỷ tham số. Hệ thống này hoạt động trên cụm máy tính chứa 16384 GPU Nvidia H100 và gặp sự cố trung bình mỗi ba giờ trong quá trình huấn luyện kéo dài 54 ngày, tổng cộng 419 lần sự cố không mong muốn.
Những sự cố này chủ yếu xuất phát từ GPU và bộ nhớ băng thông cao (HBM3). Do quy mô lớn và đồng bộ hóa cao của nhiệm vụ huấn luyện, Llama 3 dễ dàng bị gián đoạn, và một lỗi ở một GPU có thể làm gián đoạn toàn bộ quá trình huấn luyện, đòi hỏi phải khởi động lại.
Tuy nhiên, nhóm phát triển Llama 3 đã đạt được hơn 90% thời gian huấn luyện hiệu quả, nhờ vào việc hỗ trợ tự động cho việc bảo trì cụm máy tính, như nâng cấp phần mềm và hệ điều hành Linux.
Trong suốt quá trình huấn luyện 54 ngày, tổng cộng có 466 lần sự cố. Trong đó, 47 lần là sự cố dự kiến do bảo trì tự động như nâng cấp phần mềm hoặc cập nhật cấu hình và dữ liệu. 419 lần còn lại là sự cố không mong muốn, chủ yếu do lỗi phần cứng, bao gồm lỗi GPU, thành phần chính và các vấn đề liên quan đến phần cứng khác như hỏng dữ liệu im lặng và bảo trì đơn lẻ không lên kế hoạch.
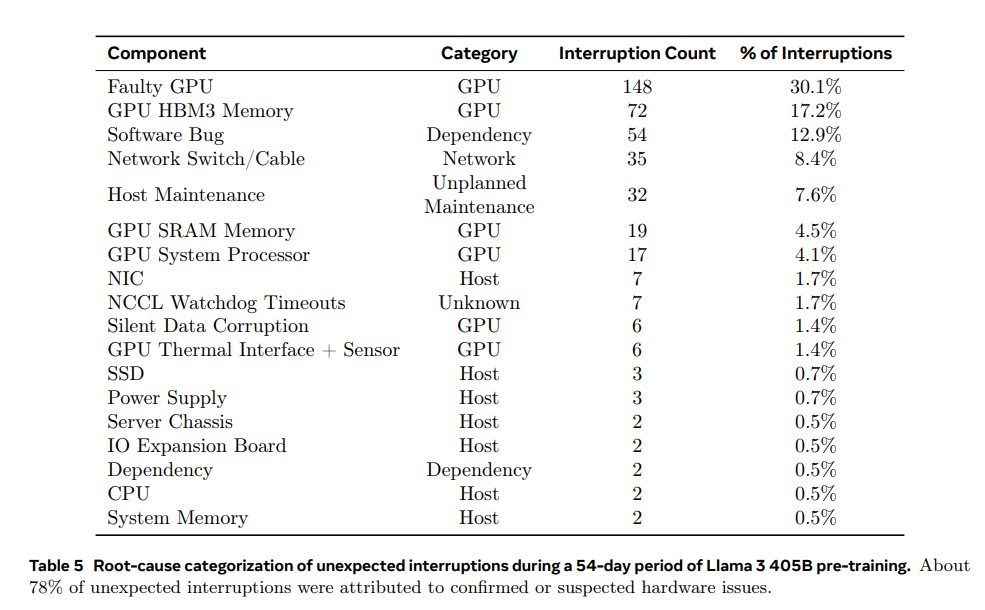
Lỗi GPU chiếm 58.7% trong số các sự cố không mong muốn, bao gồm nhiều loại lỗi khác nhau như lỗi NVLink và lỗi bộ nhớ HBM3. Điều này không có gì ngạc nhiên, vì GPU Nvidia H100 tiêu thụ khoảng 700W và chịu nhiệt độ cao. Dù có nhiều sự cố, chỉ có ba sự cố yêu cầu sự can thiệp con người đáng kể, phần lớn sự cố đều được xử lý tự động.
Các sự cố không mong muốn còn lại 41.3% là do lỗi phần mềm, cáp mạng và bộ chuyển đổi mạng. Điều thú vị là trong suốt thời gian này, chỉ có hai CPU gặp sự cố.
Dự án huấn luyện Llama 3 405B cũng đối mặt với thách thức khác từ việc hàng nghìn GPU cùng lúc thay đổi mức tiêu thụ điện năng, gây áp lực lên lưới điện của trung tâm dữ liệu.
Khi hàng nghìn GPU cùng tăng hoặc giảm mức tiêu thụ điện năng, như chờ đợi kiểm tra điểm hoàn thành hoặc kết thúc giao tiếp tập thể, hoặc bắt đầu và dừng toàn bộ nhiệm vụ huấn luyện, điều này dẫn đến biến động mức tiêu thụ điện năng lên đến hàng chục megawatt, có thể vượt quá khả năng của lưới điện.
Đây là một thách thức liên tục, nghĩa là Meta cần đảm bảo rằng trung tâm dữ liệu của họ có đủ năng lượng để duy trì việc huấn luyện mô hình 405B và các mô hình Llama lớn hơn trong tương lai. Với sự gia tăng phức tạp của các mô hình AI, nhu cầu về tài nguyên tính toán cũng tăng theo.
Để cải thiện hiệu suất, Meta đã phát triển nhiều công cụ và chiến lược tối ưu hóa, bao gồm giảm thời gian khởi động và kiểm tra điểm, sử dụng rộng rãi trình ghi chuyến bay NCCL tích hợp sẵn trong PyTorch, và nhận diện GPU chậm. NCCLX đóng vai trò quan trọng trong việc phát hiện và định vị lỗi, đặc biệt là các vấn đề liên quan đến NVLink và RoCE, do tích hợp với PyTorch cho phép theo dõi và tự động hết hạn các sự cố giao tiếp do lỗi NVLink gây ra.
Hiểu rõ hơn, trình ghi chuyến bay NCCL của PyTorch ghi dữ liệu metadata và dấu vết ngăn xếp vào bộ đệm vòng tròn, giúp chẩn đoán và giải quyết nhanh chóng các vấn đề treo và hiệu suất trong trường hợp quy mô lớn, đặc biệt là các vấn đề liên quan đến NCCLX. Ngoài ra, do Meta sử dụng kết hợp NVLink và RoCE trong mạng, việc debug vấn đề trong huấn luyện quy mô lớn trở nên phức tạp hơn. Việc truyền dữ liệu qua NVLink thường được thực hiện thông qua các lệnh tải/lưu của CUDA kernel, trong khi lỗi của GPU xa hoặc kết nối NVLink thường biểu hiện dưới dạng lệnh tải/lưu của CUDA kernel bị treo và không trả về mã lỗi rõ ràng.

NCCLX thông qua thiết kế đồng bộ chặt chẽ với PyTorch đã cải thiện tốc độ và độ chính xác trong việc phát hiện và định vị lỗi, cho phép PyTorch truy cập trạng thái nội bộ của NCCLX và theo dõi thông tin liên quan. Mặc dù không thể ngăn chặn hoàn toàn việc treo do lỗi NVLink, hệ thống sẽ theo dõi trạng thái thư viện giao tiếp và tự động hết hạn khi phát hiện ra những treo như vậy. Ngoài ra, NCCLX theo dõi hoạt động kernel và mạng của mỗi lần giao tiếp NCCLX, và cung cấp trạng thái nhanh của tập thể lỗi NCCLX, bao gồm tất cả dữ liệu đã hoàn thành và chưa hoàn thành giữa các cấp độ.
Đôi khi, vấn đề phần cứng có thể dẫn đến việc có GPU vẫn chạy nhưng tốc độ chậm, rất khó phát hiện. Một GPU chậm có thể làm chậm hàng nghìn GPU khác, thường biểu hiện dưới dạng giao tiếp bình thường nhưng chậm. Đối với vấn đề này, Meta đã phát triển công cụ để ưu tiên xử lý các giao tiếp tiềm năng từ nhóm tiến trình được chọn, giúp phát hiện và giải quyết nhanh chóng các GPU chậm, đảm bảo giảm thiểu ảnh hưởng đến hiệu suất tổng thể của huấn luyện.
Một quan sát thú vị khác là tác động của yếu tố môi trường đến hiệu suất huấn luyện quy mô lớn. Với Llama 3 405B, Meta đã nhận thấy có sự thay đổi 1-2% về thông lượng trong một khoảng thời gian nhất định trong ngày, do nhiệt độ cao vào buổi trưa ảnh hưởng đến điều chỉnh điện áp và tần số động của GPU, từ đó ảnh hưởng đến hiệu suất huấn luyện. Tuy nhiên, đây không phải là vấn đề lớn, vì việc điều chỉnh điện áp và tần số động của GPU thường chịu ảnh hưởng từ sự thay đổi nhiệt độ.
Xét đến cụm máy tính chứa 16384 GPU H100 đã trải qua 419 lần sự cố không mong muốn trong 54 ngày, với trung bình 7.76 lần mỗi ngày, chúng ta không khỏi đặt câu hỏi về tần suất sự cố của cụm máy tính Memphis Supercluster của xAI, với 100000 GPU H100. Cụm máy tính này có thể đối mặt với tần suất sự cố tăng đột biến, với số lượng linh kiện bị lỗi có thể tăng sáu lần, tạo ra thách thức lớn hơn cho việc huấn luyện AI trong tương lai.
Tuần trước, Elon Musk đã khoe khoang trên nền tảng X rằng ông đã khởi động cụm huấn luyện AI mạnh nhất thế giới, và sẽ tạo ra “AI mạnh nhất mọi chỉ số trên thế giới” trước tháng 12. Được biết, cụm máy tính Memphis Supercluster đã bắt đầu huấn luyện, sử dụng làm mát bằng chất lỏng và kiến trúc mạng liên kết RDMA độc lập.
Theo tỷ lệ quy mô GPU, cụm máy tính Memphis Supercluster của xAI có thể đối mặt với tần suất sự cố tăng đột biến, với số lượng linh kiện bị lỗi có thể tăng sáu lần, tạo ra thách thức lớn hơn cho việc huấn luyện AI trong tương lai.
Tóm tắt 5 từ khóa:
- AI
- Meta
- Llama 3
- H100 GPU
- huấn luyện
© Thông báo bản quyền
Bản quyền bài viết thuộc về tác giả, vui lòng không sao chép khi chưa được phép.
Những bài viết liên quan:




Không có đánh giá...