
Đối mặt với lo âu về tính toán, công ty AI thuộc Tsinghua đã phát triển nền tảng huấn luyện hỗn hợp với khả năng sử dụng tính toán cao nhất lên đến 97,6%.
Thực trạng và Thách thức trong Đào tạo Mô hình Lớn với Chip Heterogenerous
Vào ngày 4 tháng 7, tại Diễn đàn Hạ tầng Trí tuệ Nhân tạo Thế giới 2024, Đồng sáng lập kiêm Giám đốc Điều hành của Wuwen Xincheng, Xia Liye đã công bố nền tảng đào tạo hỗn hợp chip đa kiến trúc quy mô hàng nghìn card, đạt mức hiệu suất tối đa là 97,6% so với đào tạo đồng nhất. Đây cũng là nền tảng đầu tiên trên thế giới có khả năng đào tạo một nhiệm vụ quy mô hàng nghìn card chip đa kiến trúc, đồng thời có khả năng mở rộng đến hàng vạn card, hỗ trợ các loại chip như AMD, Huawei Kunpeng, Tiandushizhi, Musixi, Mooreline, và NVIDIA.
Hiện nay, cách tiếp cận phổ biến trong lĩnh vực đào tạo mô hình lớn trên toàn cầu là kết hợp các khung tính toán tiên tiến như PyTorch và Megatron với các card đồ họa NVIDIA để thực hiện đào tạo phân tán hiệu quả. Mặc dù NVIDIA giữ vị trí thống trị trong việc cung cấp sức mạnh tính toán cho việc đào tạo mô hình lớn, các nhà sản xuất chip trong nước như Huawei Kunpeng, Cambricon MLU, Suiyuan Technology, Haiguang DCU, và Mooreline đã dần nổi lên với các bộ xử lý AI hiệu suất cao.
Tuy nhiên, trong thực tế, việc đào tạo mô hình lớn thường yêu cầu hàng trăm đến hàng nghìn card GPU hoạt động song song. Ví dụ, mô hình cụ thể Llama3-70B có tới 70 tỷ tham số, đòi hỏi ít nhất 900 card GPU H100 liên tục làm việc trong 10 tháng. Do nhiều nguyên nhân khác nhau, việc tập hợp một lượng lớn card GPU cùng loại có thể không khả thi. Một kịch bản phổ biến hơn là chỉ có 500 card NV H100 (mỗi card cung cấp 969 TFLOPS), 400 card Huawei Ascend 910B (mỗi card 256 TFLOPS) và 700 card AMD MI250X (mỗi card 383 TFLOPS). Mặc dù không một loại card nào đủ để đào tạo mô hình Llama3-70B độc lập, việc sử dụng hỗn hợp ba loại card này có thể đáp ứng nhu cầu đào tạo.
Tuy nhiên, do sự khác biệt về cấu trúc kiến trúc và hệ sinh thái phần mềm giữa các nhà sản xuất chip, việc đào tạo hỗn hợp mô hình lớn trên chip đa kiến trúc gặp rất nhiều thách thức. Để giải quyết vấn đề này, Wuwen Xincheng đã phát triển một thư viện giao tiếp tập hợp không gian vô cực (IHCCM), hỗ trợ hai cách giao tiếp dựa trên CPU hoặc GPU.
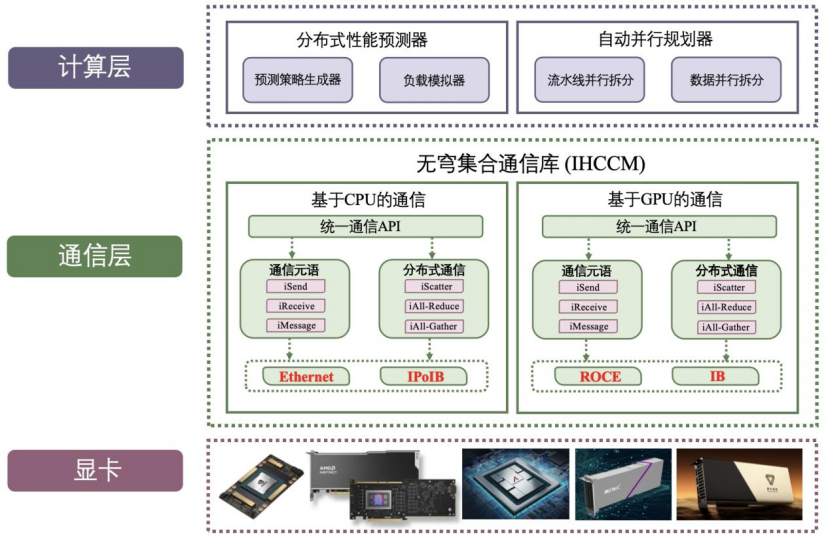
Đồ thị: Kiến trúc thư viện giao tiếp IHCCM
Trong kiến trúc này, các nút cùng loại giao tiếp thông qua các switch PCIe tốc độ cao. Việc giao tiếp giữa các nút khác nhau được thực hiện thông qua IPoIB hoặc Ethernet, đảm bảo truyền dữ liệu hiệu quả. Điều này giúp duy trì chuỗi giao tiếp ổn định và hiệu quả giữa các chip kiến trúc khác nhau.
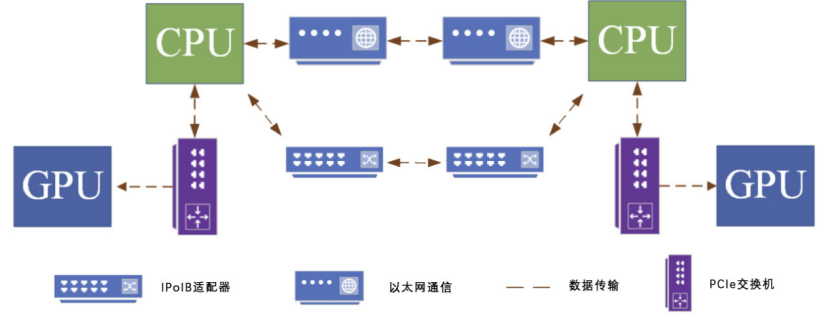
Đồ thị: Quá trình giao tiếp dựa trên CPU
Để giải quyết vấn đề giao tiếp giữa các card GPU khác nhau, chúng tôi đã thiết kế một kiến trúc giao tiếp dựa trên công nghệ RDMA, cho phép trao đổi dữ liệu hiệu quả thông qua mạng InfiniBand. Nhờ vào việc chuẩn hóa giao diện phân tán, việc giao tiếp giữa các card GPU khác nhau trở nên dễ dàng hơn.
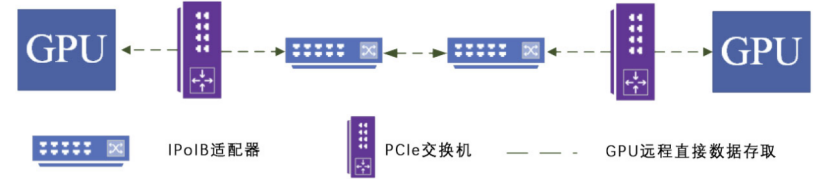
Đồ thị: Quá trình giao tiếp dựa trên GPU
Trong hệ thống đào tạo phân tán hỗn hợp, việc phân chia tác vụ dựa trên đặc điểm của mô hình và tình trạng đào tạo thực tế là một thách thức lớn. Phương pháp đào tạo dựa trên luồng làm việc (pipeline parallelism) và phân chia không đều các lớp transformer có thể giải quyết vấn đề không cân đối về sức mạnh tính toán.
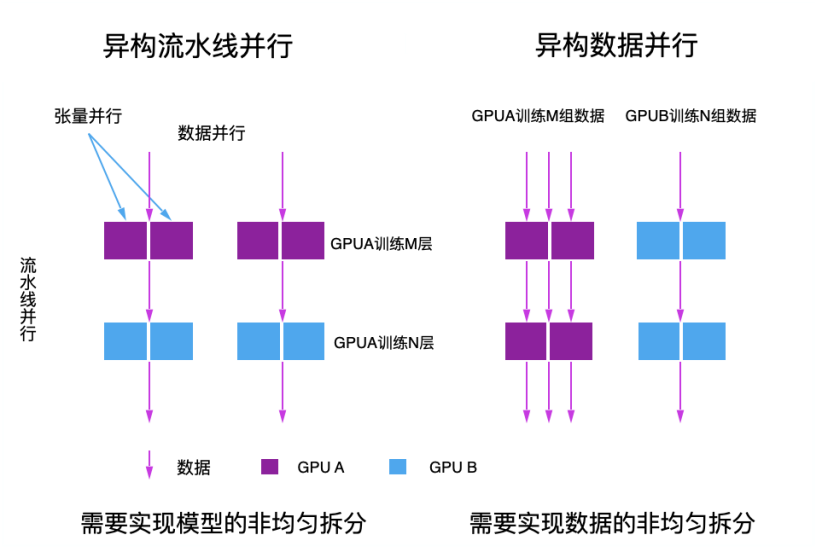
Đồ thị: Hai chiến lược song song trong đào tạo
Việc lựa chọn và kết hợp các chiến lược song song như song song dữ liệu (data parallelism), song song luồng (pipeline parallelism) và song song tensor (tensor parallelism) cũng đóng vai trò quan trọng trong việc cải thiện hiệu suất đào tạo.
Các chiến lược song song:
- Đào tạo song song dữ liệu chia nhỏ dữ liệu lớn thành nhiều phần để xử lý song song trên nhiều card GPU.
- Đào tạo song song luồng chia nhỏ mô hình thành nhiều phần để xử lý trên các card GPU khác nhau.
- Đào tạo song song tensor chia nhỏ các tham số mô hình để tăng cường hiệu suất xử lý.
Nền tảng hiện tại có thể thực hiện đào tạo mô hình llama2-7B/70B trên bất kỳ hai loại phần cứng khác nhau, tìm ra chiến lược phân tán tối ưu trên hàng nghìn card đa kiến trúc, đạt được mức hiệu suất sử dụng sức mạnh tính toán là 97,6%.
Kết luận
Thông qua việc tích hợp thêm sức mạnh tính toán đa kiến trúc, Wuwen Xincheng hy vọng sẽ tiếp tục nâng cao giới hạn của công nghệ mô hình lớn, phá vỡ giới hạn về nguồn lực đào tạo của các thương hiệu chip đơn lẻ. Trên cơ sở thành tựu hiện tại, họ tiếp tục nghiên cứu cách cải thiện hiệu suất tổng hợp của các cụm đa kiến trúc, xây dựng hạ tầng AI gốc mới thích ứng với nhiều mô hình và nhiều loại chip.
Từ khóa
- Mô hình lớn
- Chip đa kiến trúc
- Đào tạo phân tán
- Thư viện giao tiếp IHCCM
- Đào tạo hỗn hợp
© Thông báo bản quyền
Bản quyền bài viết thuộc về tác giả, vui lòng không sao chép khi chưa được phép.
Những bài viết liên quan:




Không có đánh giá...