
Karpathy lại làm nên điều kỳ diệu! Chỉ trong một ngày đã huấn luyện được GPT-2, chi phí giảm 100 lần, người dùng mạng: Nếu ông Huang tiếp tục giảm giá, sẽ thật tuyệt vời.
Giới thiệu về việc tái tạo mô hình GPT-2 bằng llm.c
Andrej Karpathy, một thành viên sáng lập của OpenAI và cựu nhà khoa học nghiên cứu, đã gần đây thử nghiệm việc tái tạo mô hình GPT-2 trong llm.c. Mô hình GPT-2 này là phiên bản đầy đủ với 15.58 tỷ tham số, được giới thiệu lần đầu vào ngày 14 tháng 2 năm 2019 trong bài đăng trên blog của OpenAI “Better Language Models and their Implications”.
Karpathy cho biết, việc huấn luyện GPT-2 vào năm 2019 là một dự án quy mô lớn đòi hỏi cả nhóm làm việc cùng nhau. Tuy nhiên, với sự cải tiến trong các lĩnh vực như tính toán (H100 GPU), phần mềm (CUDA/cuBLAS, cuDNN, FlashAttention) và dữ liệu (ví dụ: FineWeb-Edu dataset), chúng ta đã có thể tái tạo mô hình này chỉ trong 24 giờ với chi phí tổng cộng là 672 USD.
Sau khi rời OpenAI vào năm 2017 để gia nhập Tesla với vai trò Giám đốc AI, Karpathy đã trở lại OpenAI vào năm 2023 để xây dựng nhóm và ra mắt ChatGPT. Một năm sau, anh ấy lại rời khỏi OpenAI và phát triển llm.c, một mô hình đơn giản, thuần túy bằng C/CUDA với tổng khoảng 5000 dòng mã, không cần sử dụng các công cụ phức tạp như Python hay các thư viện học sâu như PyTorch/JAX hoặc huggingface/transformers.
Sau khi công bố kết quả này, Karpathy đã so sánh hiệu suất của mô hình mới với phiên bản GPT-2 từ năm 2019. Sử dụng cùng một đoạn văn từ bài đăng gốc, kết quả đầu ra của mô hình mới khá mạch lạc và chất lượng tương đương với GPT-2. Các bạn quan tâm có thể xem kết quả tại đây:
Các bước tái tạo GPT-2 bằng llm.c
Karpathy nhấn mạnh rằng việc huấn luyện GPT-2 bằng llm.c rất đơn giản do nó được viết bằng C/CUDA. Chỉ cần một thiết bị có tám GPU H100.
Nếu bạn chỉ có một GPU, bạn vẫn có thể huấn luyện mô hình nhưng sẽ mất khoảng 8 ngày thay vì 1 ngày như Karpathy. Nếu bạn sở hữu 16 GPU (ví dụ: sử dụng Lambda 1 Click Clusters), bạn có thể thực hiện huấn luyện đa nút và chỉ cần chờ đợi khoảng 12 giờ.
Trong quá trình huấn luyện, mỗi bước mất khoảng 2.75 giây và có tổng cộng 32 nghìn bước, vì vậy bạn cần chờ khoảng 24 giờ để hoàn tất.
Mỗi bước huấn luyện sẽ sử dụng khoảng 1 triệu token từ dữ liệu FineWeb-EDU và cập nhật 1.558 tỷ trọng số của mô hình, giúp mô hình dự đoán chính xác hơn các token tiếp theo. Cuối cùng, mô hình sẽ xử lý tổng cộng 32 nghìn x 1 triệu = 33.6 tỷ token.
Quá trình huấn luyện này cũng bao gồm việc chuẩn hóa và tăng tốc độ học tập trong những bước đầu tiên. Mô hình đạt được mức sử dụng flops (MFU) khoảng 50%, điều này chứng tỏ nó hoạt động rất hiệu quả.
So sánh hiệu suất giữa GPT-2 và mô hình mới
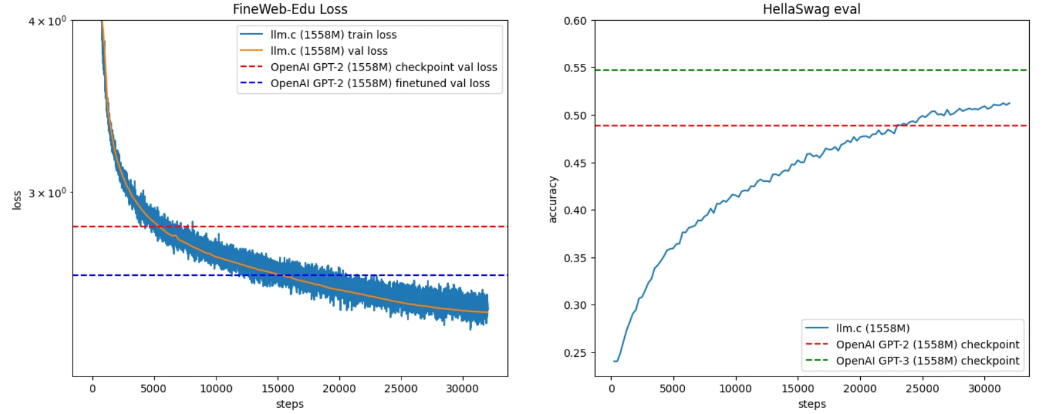
Để đánh giá hiệu suất, Karpathy đã sử dụng bộ đánh giá HellaSwag, một phương pháp phổ biến để kiểm tra khả năng của mô hình trong việc mở rộng thông tin dựa trên ngữ cảnh đơn giản. Kết quả cho thấy, mô hình mới bắt đầu vượt qua GPT-2 sau khoảng 5000 bước.
Tuy nhiên, việc so sánh này không hoàn toàn công bằng do GPT-2 được huấn luyện trên một bộ dữ liệu chưa được công bố (WebText), nên có thể có sự khác biệt đáng kể về phân phối dữ liệu. Nếu huấn luyện GPT-2 trên bộ dữ liệu mới với LR 1e-4, mất khoảng 1000 bước để giảm loss xuống dưới mức đánh dấu (loss 2.61).
Để so sánh chính xác hơn, Karpathy đề xuất sử dụng các phương pháp đánh giá bên thứ ba đáng tin cậy hơn. Kết quả cho thấy, mô hình mới đạt được hiệu suất cao hơn GPT-2 và GPT-3 (được huấn luyện trên 300 tỷ token) ở bước khoảng 25K.
Thông số kỹ thuật của mô hình
Việc huấn luyện mô hình GPT-2 bằng llm.c yêu cầu một số thông số kỹ thuật cụ thể:
- -i và -j: Dùng để chia tệp đánh dấu cho huấn luyện và kiểm tra.
- -o: Đường dẫn để ghi log và checkpoint.
- -v 250: Yêu cầu đánh giá và ghi log kiểm tra sau mỗi 250 bước.
- -s 300000: Yêu cầu lấy mẫu token sau mỗi 300 nghìn bước.
- -g 384: Đặt số lượng token cần lấy mẫu là 384.
- -h 1: Yêu cầu đánh giá HellaSwag.
- -b 16: Đặt kích thước micro-batch là 16.
- -t 1024: Đặt độ dài chuỗi tối đa là 1024 token.
- -d 1048576: Đặt kích thước tổng batch là 2^20.
- -r 0: Tắt chế độ tái tính toán.
- -z 1: Kích hoạt ZeRO-1 trên nhiều GPU.
- -c 0.1: Thiết lập suy giảm trọng số là 0.1.
- -k “cosine”: Thiết lập lịch trình học tập theo hàm cos.
- -l 0.0006: Đặt tốc độ học tập tối đa là 6e-4.
- -q 0.1: Thiết lập tỷ lệ suy giảm học tập là 10%.
- -u 700: Thiết lập thời gian tăng tốc độ học tập trong 700 lần lặp.
- -n 2000: Lưu checkpoint mô hình sau mỗi 2000 bước.
- -x 32000: Tổng số bước huấn luyện là 32 nghìn.
- -ge 1: Thiết lập chế độ tính toán Gelu.
- -y 1: Cho phép khôi phục trạng thái huấn luyện.
- -e “d48”: Khởi tạo mô hình GPT-2 với độ sâu 48.
Nếu bạn gặp phải vấn đề về bộ nhớ GPU, Karpathy khuyên bạn nên giảm kích thước micro-batch và thử nghiệm với các tùy chọn tái tính toán khác.
Tổng kết
Qua bài viết này, chúng ta đã thấy được cách Karpathy đã tái tạo thành công mô hình GPT-2 bằng llm.c, một dự án đơn giản và hiệu quả. Mặc dù việc huấn luyện mô hình lớn như GPT-2 vẫn đòi hỏi nguồn lực đáng kể, nhưng sự tiến bộ trong công nghệ đã giúp việc này trở nên dễ dàng hơn nhiều so với trước đây.
Từ khóa
- GPT-2
- llm.c
- huấn luyện mô hình
- OpenAI
- karpathy
© Thông báo bản quyền
Bản quyền bài viết thuộc về tác giả, vui lòng không sao chép khi chưa được phép.
Những bài viết liên quan:




Không có đánh giá...