Mô hình TTT: Một Cách Mới để Xử lý Dữ liệu Thứ tự
Nhóm nghiên cứu từ Stanford, UCSD, UC Berkeley và Meta đã đề xuất một kiến trúc mới, thay thế trạng thái ẩn trong mô hình RNN bằng mô hình học máy. Phương pháp này, được gọi là các lớp huấn luyện thời gian kiểm tra (Test-Time-Training layers, TTT), sử dụng việc giảm độ dốc đối với các token đầu vào để nén ngữ cảnh.

Trong mô hình truyền thống, tất cả các lớp xử lý chuỗi có thể được biểu diễn như một trạng thái ẩn được chuyển đổi theo quy tắc cập nhật. Tuy nhiên, cơ chế tự chú ý (self-attention) trong Transformer có hiệu suất tốt khi xử lý ngữ cảnh dài nhưng độ phức tạp của nó là bậc hai. Mặt khác, các lớp RNN có độ phức tạp tuyến tính nhưng khả năng biểu diễn trạng thái ẩn bị hạn chế khi ngữ cảnh trở nên dài hơn.
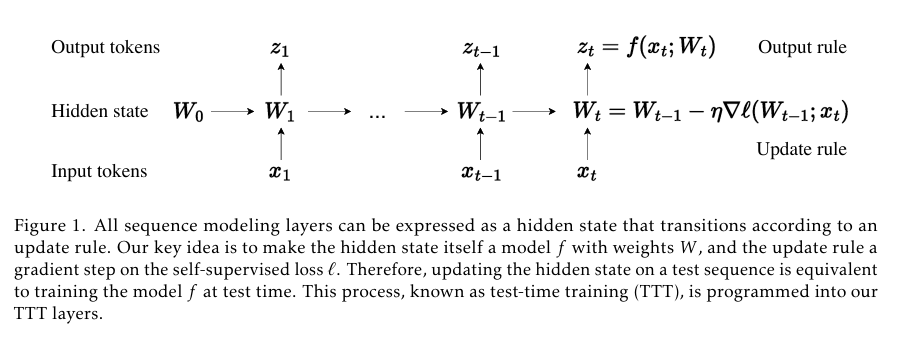
Nhóm nghiên cứu đã đề xuất một lớp xử lý chuỗi mới có độ phức tạp tuyến tính và khả năng biểu diễn trạng thái ẩn mạnh mẽ. Ý tưởng chính là cho phép trạng thái ẩn trở thành một mô hình học máy và đặt quy tắc cập nhật là một bước học tự giám sát.
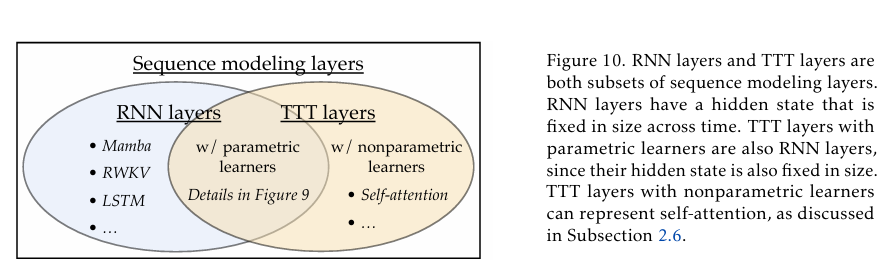
Đề xuất này bao gồm hai phiên bản: TTT-Linear và TTT-MLP. Các mô hình này đã được đánh giá trên quy mô từ 125 triệu đến 1.3 tỷ thông số và so sánh với các mô hình Transformer mạnh mẽ và RNN hiện đại như Mamba. Kết quả chỉ ra rằng, so với Mamba, TTT-Linear có độ rối thấp hơn, sử dụng ít FLOP hơn và tận dụng tốt hơn ngữ cảnh dài.

Kết quả này cho thấy tình trạng khó khăn của RNN hiện tại. Mặc dù RNN (so với Transformer) có ưu điểm về độ phức tạp tuyến tính, nhưng lợi thế này chỉ đạt được khi ngữ cảnh dài. Khi ngữ cảnh trở nên dài hơn, RNN (như Mamba) gặp khó khăn trong việc tận dụng thông tin bổ sung.
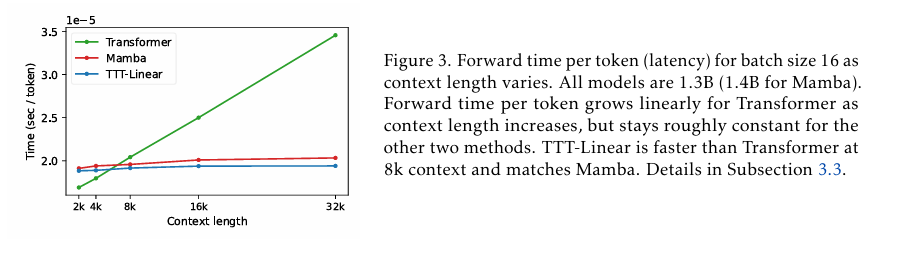
Thử nghiệm cho thấy, TTT-Linear và TTT-MLP đều phù hợp hoặc vượt trội hơn so với các mô hình cơ sở. Tương tự như Transformer, chúng có thể giảm độ rối bằng cách giới hạn nhiều token hơn, trong khi Mamba không thể làm điều này sau ngữ cảnh 16k. Sau tối ưu hóa hệ thống ban đầu, TTT Linear nhanh hơn Transformer trong môi trường 8k và tương đương với Mamba về thời gian chạy thực tế.
Các lớp TTT đã chứng minh hiệu suất xuất sắc cả về mặt lý thuyết và đánh giá thử nghiệm, đặc biệt là trong việc xử lý ngữ cảnh dài và hiệu suất phần cứng. Nếu những thách thức kỹ thuật tiềm ẩn như triển khai quy mô lớn và tích hợp có thể được giải quyết, sự chấp nhận của công nghiệp đối với TTT layer cũng sẽ tăng lên.




