Tác giả: Zhao Minghua
Nhóm nghiên cứu của Phòng thí nghiệm Alibaba thông báo và mở cửa nguồn FunAudioLLM, một khung giao diện nhằm tăng cường tương tác giọng nói tự nhiên giữa con người và các mô hình ngôn ngữ lớn (LLMs). Đây là bước tiến mới trong lĩnh vực xử lý âm thanh.
Trung tâm của khung này là hai mô hình sáng tạo: SenseVoice và CosyVoice. Hai mô hình này không chỉ thể hiện khả năng xuất sắc trong việc nhận dạng giọng nói đa ngôn ngữ, nhận dạng cảm xúc, phát hiện sự kiện âm thanh và tạo ra giọng nói tự nhiên, mà còn chứng minh độ chín muỗng và tiềm năng ứng dụng rộng rãi.
- Nhận dạng đa ngôn ngữ: Được huấn luyện bằng hơn 400.000 giờ dữ liệu, hỗ trợ hơn 50 ngôn ngữ, cải thiện độ chính xác nhận dạng lên đến 50% trong tiếng Trung và tiếng Quảng Đông.
- Nhận dạng cảm xúc: Có khả năng nhận dạng cảm xúc vượt trội, đạt hoặc vượt qua hiệu suất của mô hình nhận dạng cảm xúc tốt nhất hiện tại.
- Phát hiện sự kiện âm thanh: Khả năng nhận diện nhiều trạng thái cảm xúc và sự kiện giao tiếp như nhạc, vỗ tay, cười, khóc, v.v.
- Kiến trúc mô hình: Bao gồm Nhận dạng giọng nói tự động (ASR), Nhận dạng ngôn ngữ (LID), Nhận dạng cảm xúc (SER) và Phát hiện sự kiện âm thanh (AED), có khả năng thích ứng với nhiều ứng dụng khác nhau.
- Hợp thành đa ngôn ngữ: Được huấn luyện bằng tổng cộng hơn 150.000 giờ dữ liệu, hỗ trợ hợp thành giọng nói bằng tiếng Trung, Anh, Nhật, Quảng Đông và Hàn Quốc, hiệu quả vượt trội so với mô hình tổng hợp giọng nói truyền thống.
- Mô phỏng âm sắc nhanh chóng: Chỉ cần 3 đến 10 giây âm thanh gốc, có thể tạo ra âm sắc mô phỏng, bao gồm giai điệu và cảm xúc chi tiết, thậm chí có thể thực hiện tổng hợp giọng nói liên ngôn ngữ.
- Kiểm soát chi tiết: Hỗ trợ kiểm soát chi tiết giọng nói được tạo ra thông qua văn bản giàu hoặc ngôn ngữ tự nhiên, cải thiện đáng kể độ tinh tế về biểu cảm cảm xúc của giọng nói được tạo ra.
- Kiến trúc mô hình: Bao gồm bộ chuyển đổi hồi quy để tạo ra các ký tự âm thanh từ văn bản đầu vào; mô hình khuếch tán dựa trên ODE (đồng bộ hóa dòng) để tái tạo phổ Mel từ các ký tự âm thanh được tạo ra; và bộ mã hóa dựa trên HiFTNet để tổng hợp sóng âm.

FunAudioLLM không chỉ đột phá về mặt công nghệ, mà triển vọng ứng dụng cũng rất rộng rãi. Dựa trên các mô hình SenseVoice và CosyVoice, dự án này có thể hỗ trợ nhiều ứng dụng tương tác người-máy, chẳng hạn như dịch đa ngôn ngữ với giọng nói có cảm xúc, cuộc trò chuyện bằng giọng nói có cảm xúc, podcast tương tác và sách nói.
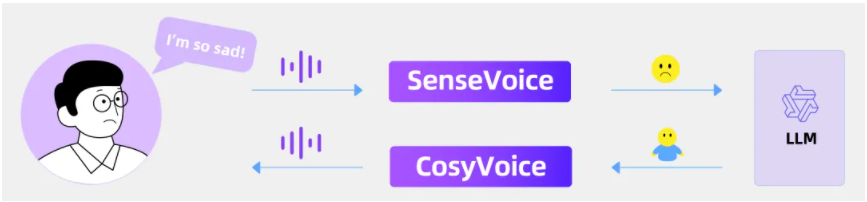
Bằng cách kết hợp SenseVoice, LLM và CosyVoice, FunAudioLLM có thể phát triển một ứng dụng trò chuyện bằng giọng nói có cảm xúc.
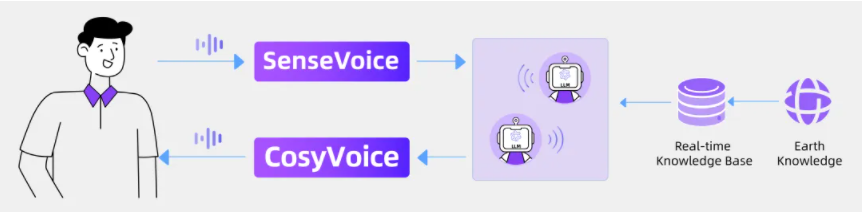
Bằng cách tích hợp SenseVoice, hệ thống đại lý đa người dùng dựa trên LLM và CosyVoice, FunAudioLLM có thể tạo ra một đài phát thanh podcast tương tác.
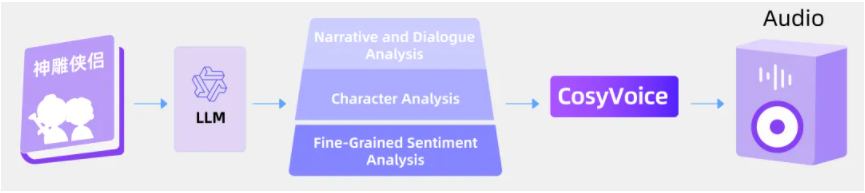
Kết hợp với khả năng phân tích văn bản của LLM và công nghệ tạo giọng nói của CosyVoice, FunAudioLLM có thể sản xuất những cuốn sách nói có sức thuyết phục mạnh mẽ hơn.
Hiện tại, các mô hình liên quan đến SenseVoice và CosyVoice đã được mở nguồn trên ModelScope và Huggingface, đồng thời mã huấn luyện, suy luận và điều chỉnh mô hình tương ứng đã được công bố trên GitHub.