
Zero One ra mắt cơ sở dữ liệu vector “Descartes” mạnh mẽ! Đứng đầu trong sáu bảng xếp hạng đánh giá uy tín.
Đột phá mới trong công nghệ lưu trữ dữ liệu vector với Descartes
Vào ngày 11 tháng 3, công ty Zero One Wywm đã công bố thành công nghiên cứu và phát triển hệ thống cơ sở dữ liệu vector dựa trên công nghệ toàn bản đồ mới, được gọi là Descartes. Hệ thống này đã xuất sắc đứng đầu trong sáu thử nghiệm dữ liệu của bảng xếp hạng ANN-Benchmarks.

Zero One Wywm cho biết, hệ thống Descartes sẽ được áp dụng vào các sản phẩm AI sắp ra mắt của họ. Trong tương lai, hệ thống này cũng sẽ được cung cấp cho cộng đồng lập trình viên.
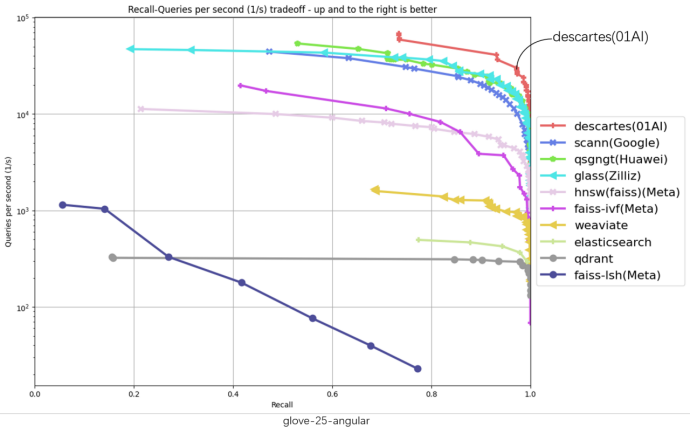
ANN-Benchmarks là công cụ kiểm tra hiệu suất cơ sở dữ liệu vector hàng đầu hiện nay, thể hiện hiệu suất của các thuật toán trên nhiều tập dữ liệu thực tế khác nhau. Hệ thống Descartes của Zero One Wywm đã dẫn đầu ở tất cả sáu thử nghiệm dữ liệu trên bảng xếp hạng ANN-Benchmarks (xem kết quả chi tiết dưới đây).
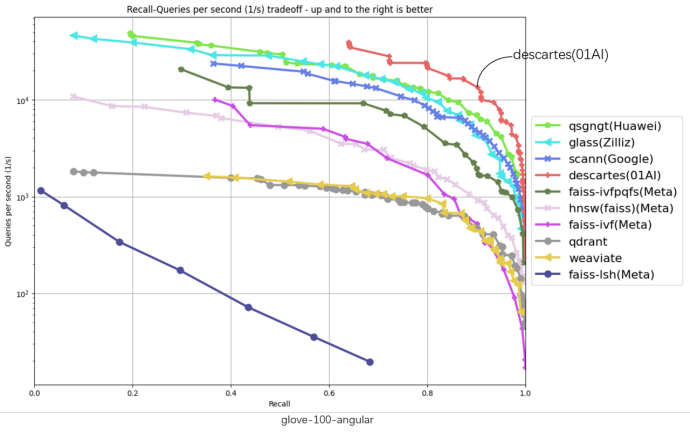
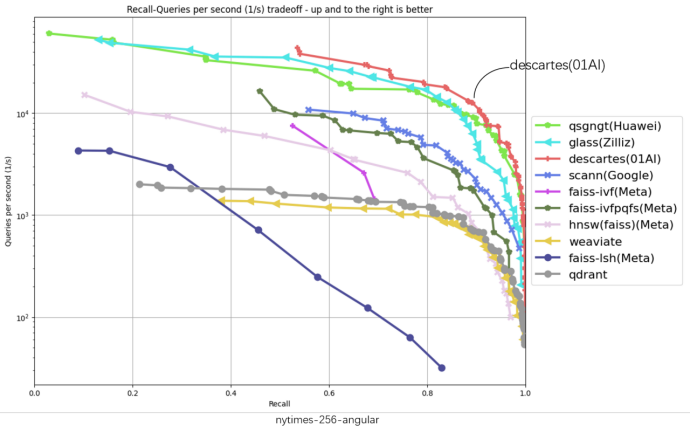
Trong sáu biểu đồ thử nghiệm trên, trục ngang đại diện cho tỷ lệ trả về, trục dọc đại diện cho số lượng yêu cầu xử lý mỗi giây (QPS). Vị trí càng cao và càng gần góc trên bên phải biểu đồ cho thấy hiệu suất thuật toán càng tốt. Có thể thấy rằng đường màu đỏ đại diện cho Descartes luôn ở vị trí cao nhất trong tất cả các biểu đồ.
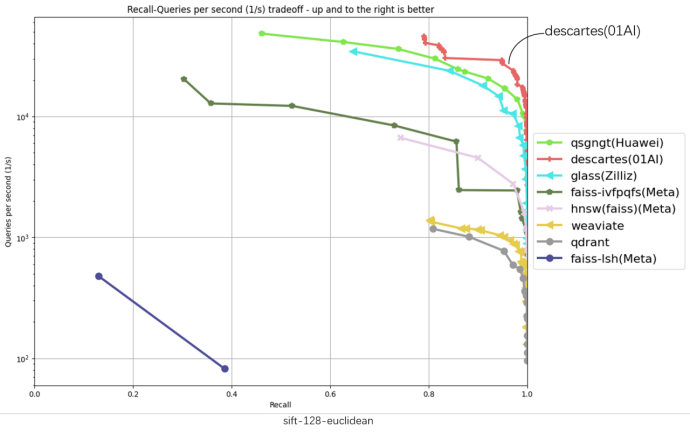
Ngoài việc cải thiện đáng kể hiệu suất so với vị trí đầu tiên ban đầu trên bảng xếp hạng, hệ thống Descartes của Zero One Wywm đã đạt được mức tăng hiệu suất hơn gấp đôi trên một số tập dữ liệu. Đặc biệt, trên tập dữ liệu gist-960-euclidean, hiệu suất của nó vượt xa vị trí đầu tiên trước đó tới 286%.
Cơ sở dữ liệu vector, còn được gọi là công nghệ tìm kiếm thông tin trong kỷ nguyên AI, là một trong những công nghệ cốt lõi của Retrieval-Augmented Generation (RAG). Cơ sở dữ liệu vector được sử dụng để lưu trữ, lập chỉ mục và truy vấn các vector nhúng được tạo từ dữ liệu phi cấu trúc như văn bản, hình ảnh hoặc âm thanh. Các vector nhúng này được tạo ra bằng cách chuyển đổi dữ liệu phi cấu trúc thành các vector đa chiều để dễ dàng tìm kiếm và truy vấn đối tượng tương tự. Khác với cơ sở dữ liệu quan hệ truyền thống, cơ sở dữ liệu vector chủ yếu phục vụ dữ liệu phi cấu trúc và sử dụng các chỉ mục tương tự để trả về kết quả truy vấn, thay vì tìm kiếm dựa trên từ khóa.
Công nghệ cơ sở dữ liệu vector có khả năng lưu trữ với chi phí thấp và tính toán hiệu suất cao, bao gồm việc lập chỉ mục vector cho mục đích tìm kiếm và truy vấn, lọc đơn cấp, phân mảnh dữ liệu, sao chép, lưu trữ hỗn hợp và API. Với sự gia tăng ứng dụng của dữ liệu phi cấu trúc, nhu cầu xử lý và phân tích loại dữ liệu này cũng đang tăng lên. Các lĩnh vực ứng dụng chính bao gồm nhận dạng khuôn mặt, hệ thống đề xuất, tìm kiếm hình ảnh, dấu vân tay video, xử lý giọng nói và xử lý ngôn ngữ tự nhiên, tìm kiếm tài liệu.
Đối với các nhà phát triển ứng dụng mô hình lớn, cơ sở dữ liệu vector là một hạ tầng quan trọng, có thể ảnh hưởng đến hiệu suất của mô hình lớn. Mặc dù mô hình lớn rất mạnh mẽ, nhưng chúng vẫn tồn tại một số hạn chế như cập nhật thông tin thực thời chậm, vấn đề bảo mật riêng tư, mất mát suy luận và hiệu suất suy luận thấp. Cơ sở dữ liệu vector giải quyết các vấn đề này bằng cơ chế cập nhật nhẹ, tính năng bảo mật riêng tư, tham chiếu kiến thức phong phú và chức năng như một bộ đệm.
Zero One Wywm cho biết, cơ sở dữ liệu vector Descartes của họ có lợi thế đáng kể so với ngành công nghiệp trong việc xử lý truy vấn phức tạp, tăng cường hiệu suất tìm kiếm và tối ưu hóa lưu trữ dữ liệu. Nó chủ yếu được sử dụng để giải quyết hai loại vấn đề chính.
Hiện tại, ngành công nghiệp chủ yếu sử dụng các phương pháp như Hash, KD-Tree, VP-Tree, nhưng hiệu quả định hướng không chính xác và độ cắt giảm không đủ. Công nghệ toàn bản đồ đa lớp và điều hướng hệ thống tọa độ của Zero One Wywm đảm bảo độ chính xác và cắt giảm hàng loạt vectơ không liên quan.
Zero One Wywm cũng đã sáng tạo chiến lược lựa chọn hàng xóm thích nghi, lấp đầy khoảng trống trong ngành. Chiến lược mới của họ cho phép mỗi nút có thể chọn hàng xóm tốt nhất dựa trên phân phối của chính nó và hàng xóm, giúp nhanh chóng hội tụ gần hơn với vector mục tiêu, từ đó tăng hiệu suất tìm kiếm vector RAG từ 15% đến 30%.
Zero One Wywm đã áp dụng giải pháp lượng hóa cấp hai để tăng cường RAG. Phương pháp này giảm phức tạp tính toán và tận dụng sức mạnh phần cứng bằng cách sử dụng lưu trữ cột để tận dụng khả năng song song của SIMD, tăng hiệu suất lên 2-3 lần so với phương pháp truyền thống PQ.
Ngoài ra, Zero One Wywm còn có các giải pháp kỹ thuật toàn diện khác như tối ưu hóa cấu trúc chỉ mục và đảm bảo tính liên thông để nâng cao hiệu suất của cơ sở dữ liệu vector Descartes.
Cơ sở dữ liệu vector Descartes của Zero One Wywm hiện đang tập trung vào việc tạo ra cơ sở dữ liệu vector hiệu suất cao, thường với quy mô dữ liệu vector từ vài triệu đến hàng chục triệu (như 20 triệu vector 128 chiều dạng số). Trong các ứng dụng thực tế, nó có các ưu điểm cốt lõi như độ chính xác và hiệu suất cao.
Cơ sở dữ liệu vector hiệu suất cao có thể dễ dàng xử lý hơn 80% các tình huống hàng ngày, như xây dựng kho kiến thức tư nhân, hệ thống dịch vụ khách hàng thông minh, đẩy nhanh quá trình huấn luyện mô hình tự lái… Ví dụ, trong chẩn đoán hình ảnh y tế, với sự phát triển không ngừng của kỹ thuật hình ảnh y tế, số lượng dữ liệu hình ảnh y tế cần được lưu trữ, tìm kiếm và phân tích ngày càng nhiều. Những dữ liệu hình ảnh này có thể được chuyển đổi thành biểu diễn vector thông qua trích xuất đặc trưng, sau đó được tìm kiếm và khớp nhanh chóng bằng cơ sở dữ liệu vector hiệu suất cao. Bác sĩ trong quá trình chẩn đoán có thể sử dụng cơ sở dữ liệu vector để tìm kiếm nhanh chóng các trường hợp và tài liệu hình ảnh tương tự, từ đó hỗ trợ bác sĩ đưa ra chẩn đoán chính xác hơn.
Zero One Wywm cho biết, cơ sở dữ liệu vector Descartes là bước đi đầu tiên của họ dựa trên RAG, sẽ được áp dụng hiệu quả trong các sản phẩm năng suất AI sắp ra mắt.
Chúng ta cùng chờ đón!
Từ khóa:
- Cơ sở dữ liệu vector
- ANN-Benchmarks
- Descartes
- Zero One Wywm
- RAG
© Thông báo bản quyền
Bản quyền bài viết thuộc về tác giả, vui lòng không sao chép khi chưa được phép.
Những bài viết liên quan:




Không có đánh giá...