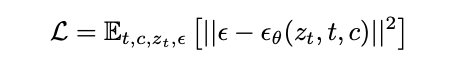Mô hình Video Sinh từ Ảnh EMO của Alibaba: Một Đột Phá trong Công Nghệ AI
Nếu bạn đã từng mơ ước biến một bức ảnh thành một video sinh động, thì công nghệ mới nhất từ Alibaba Group Intelligent Computing Research Institute có thể là câu trả lời cho mong ước đó. Mới đây, họ đã ra mắt mô hình video sinh từ ảnh EMO (Emote Portrait Alive). EMO là một khung công nghệ AI mạnh mẽ, có khả năng tạo ra các video chân dung có biểu cảm phong phú dựa trên một bức ảnh và một đoạn âm thanh bất kỳ.
Một số ví dụ ấn tượng về khả năng của EMO bao gồm việc tạo ra video của Audrey Hepburn hát say đắm, Leonardo DiCaprio biểu diễn Rap “Godzilla” đầy sức sống, Mona Lisa hùng hồn phát biểu, và Gao Qiangsheng giả dạng thành Luo Xiang giảng pháp luật.
Để huấn luyện mô hình này, Alibaba đã xây dựng một bộ dữ liệu đa dạng và lớn với hơn 250 giờ video và hơn 150 triệu bức ảnh. Bộ dữ liệu này bao gồm nhiều loại nội dung như bài giảng, cảnh phim, và màn trình diễn âm nhạc, cùng với nhiều ngôn ngữ khác nhau như tiếng Trung và tiếng Anh. Sự đa dạng này giúp đảm bảo rằng mô hình có thể nắm bắt được nhiều biểu cảm khuôn mặt và phong cách âm nhạc khác nhau.
Hiện tại, mô hình EMO đã được công bố trên arXiv, và một kho lưu trữ tương tự cũng xuất hiện trên GitHub với tên gọi EMO. Tuy nhiên, kho lưu trữ này vẫn chưa có mã nguồn thực sự, gây ra một số tranh cãi trong cộng đồng lập trình viên.
Alibaba đã giới thiệu chi tiết về quá trình huấn luyện của EMO trong báo cáo khoa học của mình. Họ đã thiết kế một khung công nghệ mới nhằm tạo ra video sinh động với các biểu cảm khuôn mặt tinh tế và chuyển động đầu tự nhiên. Phương pháp này không phụ thuộc vào các biểu diễn trung gian hoặc xử lý tiền kỳ phức tạp, giúp đơn giản hóa quy trình tạo video.
Mô hình EMO sử dụng phương pháp tạo video dựa trên phân tán để tạo ra video từ một bức ảnh và một đoạn âm thanh. Phương pháp này tận dụng thông tin trong âm thanh để tạo ra các chuyển động khuôn mặt phong phú. Ngoài ra, Alibaba còn thêm các cơ chế kiểm soát ổn định như bộ điều khiển tốc độ và bộ điều khiển khu vực khuôn mặt để tăng cường sự ổn định trong quá trình tạo video.
Phương pháp tạo video dựa trên phân tán đã chứng minh hiệu quả trong nhiều lĩnh vực như tổng hợp hình ảnh, chỉnh sửa hình ảnh, tạo video, và thậm chí là tạo nội dung 3D. Alibaba đã áp dụng phương pháp này trong EMO để tạo ra video sinh động từ một bức ảnh.
Các kỹ thuật tạo video dựa trên phân tán đã được nghiên cứu và cải tiến liên tục. Phương pháp Diffusion-in-Transformer (DiT), sử dụng Transformer kết hợp với mô-đun thời gian và 3D convolution, đã đạt được kết quả đáng kinh ngạc trong việc tạo video từ văn bản. Các nghiên cứu khác cũng đã khám phá cách áp dụng phương pháp tạo video dựa trên phân tán để tạo video khuôn mặt sinh động, chứng tỏ khả năng mạnh mẽ của mô hình này.
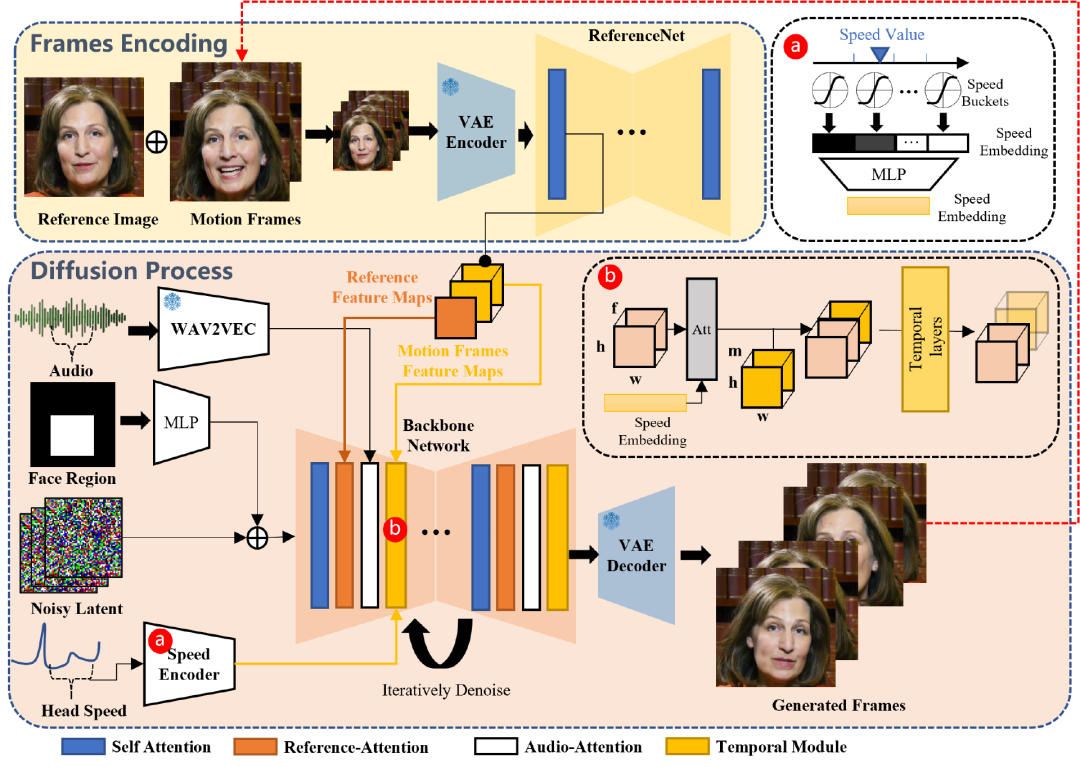
EMO bao gồm hai giai đoạn chính. Giai đoạn đầu tiên là mã hóa khung, trong đó ReferenceNet được sử dụng để trích xuất đặc trưng từ bức ảnh tham chiếu và các khung di chuyển. Giai đoạn thứ hai là quá trình phân tán, trong đó bộ mã hóa âm thanh tiền huấn luyện xử lý các nhúng âm thanh. Mặt nạ khu vực khuôn mặt và nhiễu đa khung được sử dụng để kiểm soát việc tạo hình ảnh khuôn mặt. Tiếp theo là việc sử dụng mạng chính để thực hiện việc loại nhiễu.
EMO sử dụng Stable Diffusion (SD) làm khung cơ sở. SD là một mô hình T2I (text-to-image) phổ biến, được phát triển từ mô hình Variational Autoencoder (VAE). SD sử dụng VAE để giảm chi phí tính toán đồng thời duy trì chất lượng hình ảnh cao.
Quá trình huấn luyện của EMO chia thành ba giai đoạn. Giai đoạn đầu tiên là tiền huấn luyện hình ảnh, trong đó mạng chính, ReferenceNet, và bộ định vị khuôn mặt được huấn luyện. Giai đoạn thứ hai là huấn luyện video, trong đó các mô-đun thời gian và lớp âm thanh được kết hợp. Giai đoạn cuối cùng là việc tích hợp lớp tốc độ, trong đó chỉ có mô-đun thời gian và lớp tốc độ được huấn luyện.
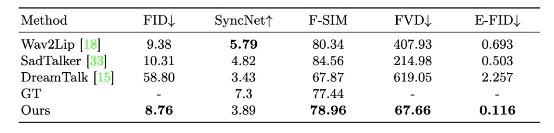
Kết quả thử nghiệm cho thấy EMO vượt trội so với các mô hình tạo video khuôn mặt khác về cả chất lượng video và độ trung thực của khuôn mặt. Mặc dù EMO chưa hoàn hảo, nhưng nó chắc chắn là một bước tiến quan trọng trong lĩnh vực tạo video sinh động từ ảnh.