
Phân tích phương pháp và lộ trình tái hiện Sora.
Sora: Sự Khởi Đầu của Thời Đại Đa Phương Tiện trong AI
Mở đầu năm Rồng, sự xuất hiện của Sora đã thắp lên những tia sáng mới trong lĩnh vực đổi mới công nghệ. Bài viết này tập trung phân tích nguyên lý cốt lõi, phương pháp thực hiện của Sora và dự đoán tương lai phát triển của nó.
Từ các đoạn video hiện tại mà Sora đã trình diễn, có thể thấy bộ dữ liệu được sử dụng có chất lượng và đa dạng rất tốt. So sánh giữa video được tạo ra với một phần của Unreal Engine (UE), chúng ta có thể suy đoán rằng bộ dữ liệu này chứa một tỷ lệ nhất định của dữ liệu UE. Con người sống trong thế giới thực, có kiến thức cơ bản về không gian ba chiều, nhưng nếu để mô hình lớn học từ video hai chiều, do hạn chế từ góc nhìn đơn, mô hình khó giữ được tính nhất quán ba chiều. Hệ thống vật lý của UE dựa trên việc giải phương trình động lực học, bao gồm nhiều quy luật vật lý và thông tin chính xác. Khi đưa dữ liệu từ UE vào mô hình lớn, qua quá trình nén của mạng thần kinh sâu, mô hình có thể trừu tượng hóa ra một số quy luật vật lý tiềm ẩn, mặc dù chưa chính xác như hệ thống vật lý.
Yếu tố quyết định chất lượng dữ liệu video không phải là video chính nó, mà là mô tả chi tiết về nội dung video. Khi OpenAI phát triển DALL-E 3, họ đã công bố bài báo “Improving Image Generation with Better Caption”, trong đó nhấn mạnh rằng mô hình tạo ảnh từ văn bản không thể tạo ra hình ảnh theo yêu cầu người dùng vì chất lượng dữ liệu huấn luyện không đủ, chủ yếu do mô tả văn bản thô sơ và không chính xác. Để giải quyết vấn đề này, OpenAI đã huấn luyện một mô hình Image-caption, một loại mô hình tự hồi quy giống như GPT, encoder sử dụng phần mã hóa hình ảnh của CLIP, có khả năng ánh xạ hình ảnh từ không gian pixel đến không gian biểu diễn ngữ nghĩa đối ứng, sau đó tạo ra mô tả văn bản chi tiết phù hợp với nội dung hình ảnh. Thực tế chứng minh, việc sử dụng cặp dữ liệu văn bản-hình ảnh chất lượng cao để huấn luyện lại DALL-E đã cải thiện đáng kể hiệu quả của mô hình tạo ảnh từ văn bản. Trong quá trình huấn luyện Sora, họ cũng đã sử dụng mô hình mô tả văn bản-video tương tự để nâng cao chất lượng mô tả văn bản, đạt được kết quả đáng kể.
Xử lý dữ liệu video là điểm sáng và đột phá lớn nhất của Sora.
Bước 1: Nén
Dữ liệu thô của video rất lớn, chúng ta đầu tiên nén nó bằng VAE (Biến phân tự mã hóa) vào không gian ẩn (latent space). Không gian ẩn này có kích thước nhỏ hơn nhiều so với kích thước của đối tượng đầu vào, đây là một biểu diễn nén của đối tượng đầu vào. Chúng ta biết rằng không gian pixel của video chứa rất nhiều thông tin dư thừa, ví dụ như giá trị của các ô pixel liền kề thường rất giống nhau, không gian ẩn là một cách rất tốt để xử lý dữ liệu phức tạp có độ cao lớn, đồng thời chúng ta cũng cần đảm bảo rằng khi giải mã, có thể khôi phục dữ liệu gốc từ biến ẩn, do đó tỷ lệ nén thích hợp rất quan trọng, nén quá nhiều sẽ làm giảm chất lượng dữ liệu được khôi phục, cụ thể nên nén đến bao nhiêu chiều là một vấn đề kỹ thuật, cần thử nghiệm qua nhiều thí nghiệm. Ưu điểm của VAE là, biểu diễn trong không gian ẩn không phải là một điểm mà là một phân phối xác suất, thông qua việc điều chỉnh điểm mẫu, chúng ta có thể kiểm soát đặc tính của dữ liệu được tạo ra, cung cấp một khung lý thuyết tốt hơn để hiểu và kiểm soát quá trình tạo ra.
Bước 2: Phân chia
OpenAI xem dòng video như một khối ba chiều bao gồm tọa độ không gian x, y và tọa độ thời gian t, và chia nó thành nhiều mảnh nhỏ gọi là spacetime latent patches. Đây là điểm sáng nhất của Sora, nó xử lý thời gian và không gian như các biến ngang hàng, thống nhất ngôn ngữ về phân chia không gian và thời gian. Trước đây, các mô hình tạo ra thường xem video như một chuỗi khung hình liên tiếp, tạo ra video liên tục bằng cách sử dụng kỹ thuật tạo khung chính, tăng cường và giảm cường độ, và kỹ thuật chèn khung. Phương pháp này xử lý không gian và thời gian một cách riêng biệt, tương tự như xử lý video thành một loạt các hình động GIF, tạo ra video có động tác nhỏ, thời gian ngắn, khó duy trì tính liên tục trong thời gian dài, và cần cắt tất cả video thành cùng một kích thước để xử lý. Trái lại, bằng cách chia thành các mảnh, chúng ta có thể xử lý video với thời gian khác nhau, độ phân giải và tỷ lệ khung hình khác nhau, ý tưởng này lấy cảm hứng từ nghiên cứu ban đầu của Google DeepMind về NaViT và ViT (Trực quan hóa Transformer), OpenAI đã phát triển nó thành một cách biểu diễn hiệu quả và có khả năng mở rộng cho dữ liệu đa phương tiện.
Bước 3: Tokenization
Chuyển các mảnh đã chia thành một dãy một chiều, đây là nơi chúng ta lấy cảm hứng từ MAGVIT-v2 của Google, nó sử dụng một CNN 3D tạm thời có tính chất nhân quả để mã hóa video và hình ảnh, nhằm thích nghi tốt hơn với nhiệm vụ có tính nhân quả và chuỗi thời gian.
Khung kiến trúc của Sora sử dụng mô hình Diffusion Transformer (DiT) để làm sạch trong không gian ẩn, sau đó kết nối với mô hình VAE để khôi phục dữ liệu video gốc. Mô hình làm sạch diffusion tập trung vào module cốt lõi thường sử dụng kiến trúc U-Net, đây là một mạng nơron convolutional (CNN) được sử dụng trong phân loại hình ảnh. CNN nổi tiếng vì có một thiên kiến tổng hợp, tức là sở hữu một kiến thức tiền nghiệm, giúp CNN duy trì tính cục bộ không gian (giữ vị trí của các đối tượng liên quan) và tính bất biến dịch chuyển (giữ thông tin hình ảnh gốc). Thông thường, kiến trúc transformer thiếu thiên kiến tổng hợp này, do đó kém bền vững hơn trong các tác vụ hình ảnh so với CNN, nhưng cơ chế chú ý tự động của transformer có một tiềm năng mạnh mẽ: càng sâu mạng, transformer càng học được tìm kiếm thông tin từ các pixel xa hơn, từ đó học được các kiến thức tiền nghiệm. Trong bài báo ViT của Google, đã đề cập rằng khi kích thước tập dữ liệu nhỏ, ViT hoạt động rõ ràng kém hơn CNN, nhưng khi kích thước dữ liệu lớn hơn 21k, khả năng của ViT tăng lên, chứng minh rằng mô hình lớn trong lĩnh vực hình ảnh cũng có khả năng bùng nổ. Bài báo DiT của Bill Peebles và Xie Saining đề cập rằng thiên kiến tổng hợp của U-Net không quan trọng đối với hiệu suất của mô hình diffusion, có thể thay thế bằng thiết kế tiêu chuẩn của transformer.

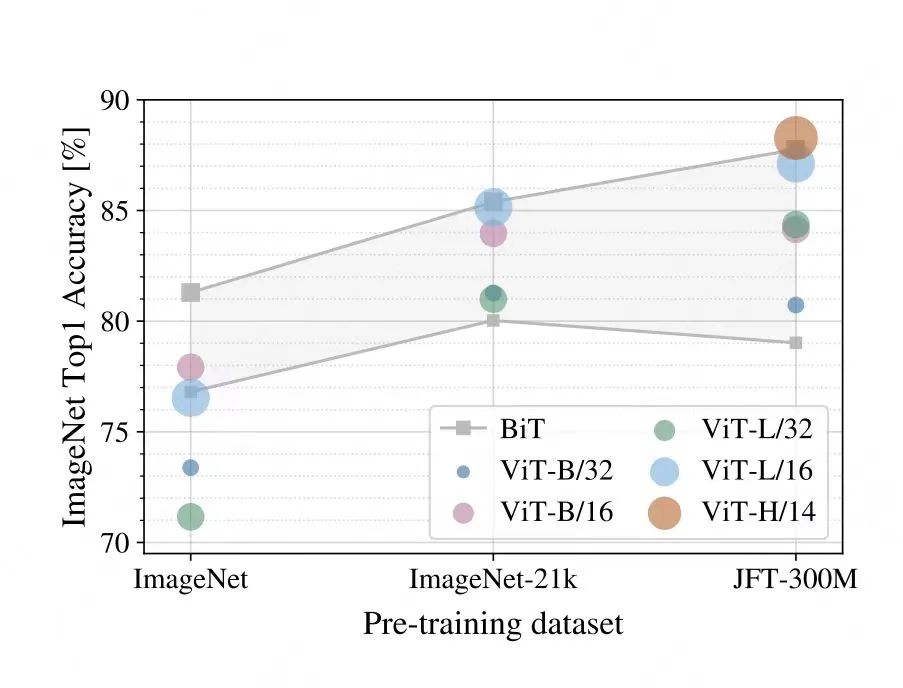
Kiến trúc ViT của Google và kết quả thí nghiệm
Mô hình Videopoet của Google sử dụng mô hình dự đoán tự hồi quy dựa trên transformer tương tự như mô hình lớn ngôn ngữ, mặc dù Sora đánh giá cao khả năng mở rộng của transformer, nhưng tại sao họ lại chọn xây dựng mô hình diffusion thay vì mô hình dự đoán tự hồi quy? Điều này có thể thấy trong bài báo DALL-E, OpenAI đã thử nghiệm cả mô hình dự đoán tự hồi quy và mô hình diffusion khi huấn luyện mô hình tạo ảnh từ văn bản DALL-E, họ phát hiện rằng mô hình diffusion có hiệu suất tính toán cao và chất lượng mẫu tạo ra tốt. Mô hình dự đoán tự hồi quy tập trung vào việc tạo ra dữ liệu chuỗi, nó sử dụng dữ liệu phía trước trong chuỗi để dự đoán dữ liệu phía sau, quá trình tính toán là tuần tự, trong khi mô hình diffusion tập trung vào việc mô phỏng quá trình lan truyền dữ liệu để tạo ra mẫu dữ liệu mới, bao gồm quá trình tiến (chuyển đổi dữ liệu thành nhiễu dần) và quá trình ngược (khôi phục dữ liệu từ nhiễu), nó không phụ thuộc vào thứ tự của chuỗi mà thay vào đó học phân phối dữ liệu để tạo ra mẫu mới, quá trình tính toán là song song. Từ kết quả thí nghiệm, mô hình dự đoán tự hồi quy hoạt động xuất sắc trong các tác vụ ngôn ngữ tự nhiên, trong khi mô hình diffusion tỏ ra vượt trội hơn trong việc tạo ra dữ liệu đa phương tiện. Thông tin ngôn ngữ có mật độ lớn hơn, ngữ nghĩa phong phú hơn, mô hình dự đoán tự hồi quy thích hợp hơn để bắt mối quan hệ phụ thuộc dài hạn và phức tạp, trong khi dữ liệu video có độ dư thừa lớn hơn, tính liên tục, liên quan và tương đồng giữa các pixel cũng cao hơn, mô hình diffusion hoạt động hiệu quả hơn trong các tác vụ này, tốc độ tạo ra cũng nhanh hơn. Nếu nói DiT là họa sĩ, thì transformer là tư duy của anh ấy, chịu trách nhiệm tinh lọc đặc trưng và cấu trúc, diffusion giống như cây cọ của anh ấy, chịu trách nhiệm về độ chân thật của bức tranh.
Kích thước mô hình
Mô hình dự đoán tự hồi quy thường có số lượng tham số lớn hơn mô hình diffusion, về kích thước mô hình Sora cũng có nhiều thảo luận, một suy đoán hợp lý là nó nhỏ hơn mô hình dự đoán tự hồi quy LLM, nhưng vì cần mở rộng mô hình transformer để trích xuất đặc trưng, nên nó lớn hơn mô hình diffusion dựa trên U-Net, có thể ở mức hàng tỷ. Mặc dù kích thước mô hình và số lượng token nhỏ hơn so với mô hình ngôn ngữ lớn, nhưng token video là mô hình không gian-thời gian ba chiều, độ dài chuỗi lớn hơn, cộng thêm độ phức tạp trong quá trình xử lý dữ liệu video, lượng tính toán rất lớn, nhu cầu về sức mạnh tính toán vẫn rất lớn.
Từ phân tích kỹ thuật trên, chúng ta có thể thấy được ý tưởng thiết kế đằng sau Sora. Mặc dù nhiều module của Sora đã lấy cảm hứng từ kết quả nghiên cứu của Google, nhưng tại sao cuối cùng lại là OpenAI chứ không phải Google đã biến nó thành hiện thực? OpenAI không lặp lại việc phát triển công nghệ đơn lẻ, mà lựa chọn đứng ở một góc độ cao hơn, kết hợp lại các công nghệ đã có. Họ không giới hạn việc tạo video trong việc xử lý từng khung hình, mà nâng lên việc mô phỏng thế giới vật lý, không chỉ tối ưu hóa công nghệ đơn lẻ, mà còn khám phá cách mở rộng ở mức độ kiến trúc và áp dụng vào mọi chi tiết (kiến trúc nào có thể hỗ trợ mở rộng, dữ liệu như thế nào để đạt được khả năng mở rộng, mô hình như thế nào để đạt được khả năng mở rộng). Sam Altman trong cuộc phỏng vấn đã đề cập, OpenAI có thể dự đoán khả năng mở rộng, sau khi xác nhận ở quy mô nhỏ, họ có thể dự đoán khả năng mở rộng. Kết quả lớn là do công nghệ nghiên cứu và cải tiến liên tục.
Trong các cuộc thảo luận về Sora, chúng ta đã thấy sự phân chia ngày càng rõ rệt giữa lý thuyết gia và thực nghiệm gia, điều này tương tự như sự hoài nghi của nhà lý thuyết vật lý đối với nhà vật lý thực nghiệm: “Kết quả thực nghiệm của bạn thiếu cơ sở lý thuyết hoàn chỉnh.” Nhà vật lý thực nghiệm phản bác lại nhà lý thuyết: “Nghiên cứu lý thuyết của bạn chưa cung cấp bằng chứng thực nghiệm mạnh mẽ.” OpenAI rõ ràng là một nhóm thực nghiệm kiên định. GPT không học hệ thống từ ngữ, ngữ pháp, cấu trúc câu, nhưng lại nắm bắt được ngôn ngữ; không học lý thuyết lập trình, cấu trúc dữ liệu, nhưng lại có thể viết mã; tương tự, Sora không học quy luật vật lý, mô hình 3D, theo dõi và render ánh sáng, nhưng lại có thể tạo ra video. Nếu UE5 là một động cơ được thiết kế và tinh chỉnh thủ công và chính xác, thì Sora là sản phẩm hoàn toàn dựa trên việc học từ dữ liệu, mặc dù nó vẫn còn nhiều hạn chế, nhưng chúng ta vẫn có thể đẩy cao giới hạn của nó bằng cách mở rộng mô hình.
Feynman đã đề xuất một giả thuyết: “Những gì tôi không thể tạo ra, tôi không hiểu.” Có lẽ, sự khác biệt lớn nhất giữa trí tuệ silicon và trí tuệ con người nằm ở hướng phát triển của trí tuệ: con người hiểu các nguyên tắc và tri thức cơ bản trước, sau đó tạo ra hệ thống và thế giới; trong khi trí tuệ silicon học từ những thứ chúng ta tạo ra, tái hiện những sáng tạo của chúng ta, cuối cùng đạt đến sự hiểu biết về chúng.
Trong báo cáo kỹ thuật của Sora, nó được định nghĩa là một mô phỏng thế giới, việc Sora có phải là mô phỏng thế giới hay không đã gây ra nhiều tranh luận. Năm 2018, David Ha và Jürgen Schmidhuber đã công bố bài báo “World Models”, nhưng họ không đưa ra định nghĩa cụ thể về “mô phỏng thế giới”, mà đã đưa khái niệm mô hình tâm trí vào quá trình xây dựng mô hình máy học. Nếu chúng ta hiểu mô phỏng thế giới như là mô hình tâm trí mà con người xây dựng trong não bộ về thế giới xung quanh, thì rõ ràng Sora chưa đạt đến tiêu chuẩn này. Theo mô tả kỹ thuật, OpenAI không có ý định biến Sora thành mô phỏng thế giới hoàn toàn trưởng thành. Giá trị cốt lõi của mô phỏng thế giới nằm ở khả năng tạo ra dữ liệu tổng hợp, tức là tạo ra dữ liệu bằng cách mô phỏng chính xác thế giới vật lý, khả năng này trong quá trình mở rộng quy mô đóng vai trò quan trọng trong việc huấn luyện mô hình lớn hơn như GPT-5.
Cách đây vài ngày, một người dùng đã thực hiện thí nghiệm thú vị, sử dụng Gemini của Google để phát hiện lỗi trong video của Sora, qua đó có thể thấy khả năng tạo video của Sora mạnh hơn, trong khi khả năng hiểu video của Gemini mạnh hơn. Chúng ta suy đoán về xu hướng phát triển trong tương lai của các dòng GPT và Gemini.
Thiết kế kiến trúc MoE (Mixture of Experts) của GPT-5 có thể sử dụng các expert khác nhau để chịu trách nhiệm cho các tác vụ tạo video và hiểu video, mô hình diffusion chịu trách nhiệm cho việc tạo video, mô hình dự đoán tự hồi quy chịu trách nhiệm cho việc phân tích nội dung video, và hai expert này có thể kiểm tra lẫn nhau để cải thiện hiệu suất tổng thể. So với Gemini, có thể Gemini sẽ thiên về sử dụng mô hình dự đoán tự hồi quy thống nhất để xử lý các tác vụ video. Chúng ta đã phân tích trước đây, đối với tác vụ tạo video, mô hình diffusion hoạt động hiệu quả hơn mô hình dự đoán tự hồi quy, một giải thích có thể là mô hình dự đoán tự hồi quy cần xử lý mối quan hệ phụ thuộc dài hạn khi dự đoán token tiếp theo, yêu cầu cửa sổ ngữ cảnh dài hơn, và công nghệ hiện tại chưa thể đáp ứng hoàn toàn nhu cầu này, trong tương lai với việc tăng cửa sổ ngữ cảnh, chúng ta có lý do để tin rằng mô hình dự đoán tự hồi quy sẽ có nhiều không gian cải thiện trong việc tạo ra dữ liệu đa phương tiện, có thể trong tương lai tạo ra ngôn ngữ tự nhiên và tạo ra dữ liệu đa phương tiện sẽ thống nhất dưới khung dự đoán tự hồi quy.
Dựa trên điều này, chúng ta suy đoán rằng kiến trúc MoE của GPT-5 có thể chứa nhiều expert hơn, mô hình sẽ mỏng hơn một chút, trong khi kiến trúc MoE của Gemini có thể chứa ít expert hơn, mô hình sẽ dày hơn một chút.
Trong quá trình huấn luyện DALL-E và Sora, công nghệ CLIP đóng vai trò then chốt, giúp OpenAI thực hiện việc liên kết đa phương tiện thông qua việc học so sánh. Phương pháp huấn luyện của Google Gemini là token hóa dữ liệu từ các phương tiện khác nhau và trộn chúng vào mô hình lớn, cho phép mô hình tự động xây dựng mối liên kết hoặc tương đồng giữa các phương tiện trong không gian ẩn. Nếu việc học đa phương tiện của OpenAI là sự liên kết cố định sau khi huấn luyện, vì nó được xây dựng một cách cố tình trong quá trình huấn luyện mô hình, thì chiến lược huấn luyện của Google giống như sự liên kết tự nhiên, cho phép mô hình tự học và thích ứng mà không cần chỉ dẫn rõ ràng, đó là lý do tại sao Gemini được gọi là “đa phương tiện gốc”. Phương pháp huấn luyện của Gemini ban đầu có thể gặp thách thức, ví dụ như liên kết không chính xác hoặc lỗi, nhưng tiềm năng lâu dài của nó rất lớn. Tương tự như hiện tượng chuyển pha vật lý, khi đạt đến một điểm giới hạn, trạng thái của hệ thống sẽ thay đổi cơ bản, hiện tại chúng ta vẫn không thể xác định chính xác quy mô mô hình cần đạt và thời điểm nó hội tụ về trạng thái ổn định. Hai luồng công nghệ này sẽ ảnh hưởng như thế nào đến sự phát triển của AGI trong tương lai, chắc chắn là một vấn đề đáng chú ý.
1. Sự ra đời của Sora đánh dấu sự chuyển mình của ứng dụng AI từ thời kỳ văn bản sang thời kỳ đa phương tiện.
2. AI-Native đang dần hình thành, khi video tạo ra vẫn còn ở giai đoạn 2-4 giây, chúng ta cần cân nhắc việc tích hợp nó với các pipeline chỉnh sửa video hoặc sản xuất 3D hiện tại, nhưng khi video tạo ra bước vào thời đại phút, nó chính là động cơ và quy trình làm việc mới.
3. Việc tạo video sẽ tách ra thành hai đường đua, một là tạo ra video có vẻ đẹp thị giác, hai là mô phỏng và dự đoán thế giới vật lý thực tế. Đường đua thứ hai còn một chặng đường dài phía trước, đường đua đầu tiên đã đạt được mức độ sử dụng, trong thế giới AI ảo, chúng ta không yêu cầu sự nhất quán hoàn hảo với thế giới thực.
4. Chuỗi sản xuất video dựa trên Sora vẫn còn tiềm năng phát triển lớn, làm thế nào để thực hiện kiểm soát tinh vi ở cấp độ vật liệu và pixel, tạo ra và chỉnh sửa sửa đổi, chúng ta mong đợi sự ra đời của các mô hình nguồn mở xuất sắc, cũng như sự phát triển phồn thịnh của cộng đồng tương tự như cộng đồng tạo ảnh từ văn bản, có nhiều sinh thái như LoRa và ControlNet xuất hiện.
5. Rào cản và chi phí sáng tạo đã giảm đáng kể, một kỷ nguyên mà mọi người đều có thể tạo phim và trò chơi sắp tới, mọi ý tưởng và tài năng đều sẽ được thể hiện, hệ sinh thái nội dung sẽ tăng trưởng bùng nổ.
6. Hiện tại, việc tạo video vẫn cần thời gian chờ đợi khá dài, nếu tương lai có thể tạo ra video ngay lập tức, chúng ta sẽ thực sự bước vào Metaverse, sống trong một thế giới ảo tương tác, cá nhân hóa và liên tục tạo ra.
7. Nếu bộ mô phỏng vật lý có thể mô phỏng chính xác thế giới thực, trí tuệ có thân thể sẽ ở rất gần với chúng ta.
Từ khóa:
- Đa phương tiện
- AI-Native
- Sora
- Mô hình diffusion
- Thế giới ảo
© Thông báo bản quyền
Bản quyền bài viết thuộc về tác giả, vui lòng không sao chép khi chưa được phép.
Những bài viết liên quan:



Không có đánh giá...