
Chỉ cần “nhanh”! ByteDance công bố mô hình mở sinh văn bản-hình ảnh, nhanh chóng leo lên bảng xếp hạng Hugging Face Spaces.
SDXL-Lightning: Một mô hình tạo ảnh dựa trên văn bản với tốc độ và chất lượng chưa từng có
Mình rất vui được chia sẻ với các bạn về mô hình tạo ảnh mới nhất của chúng tôi – SDXL-Lightning, một mô hình đã đạt được tốc độ và chất lượng chưa từng có và hiện đang mở cửa cho cộng đồng sử dụng.

Mô hình này có thể được truy cập tại đây, và bài báo khoa học liên quan có thể tìm thấy tại đây.
Trí tuệ nhân tạo (AI) tạo ra những hình ảnh tuyệt vời và video từ lời nhắc văn bản đang thu hút sự chú ý toàn cầu. Các mô hình tạo hình ảnh tiên tiến hiện nay thường dựa trên quá trình khuếch tán (diffusion), một quy trình lặp lại chuyển đổi nhiễu thành mẫu hình ảnh. Tuy nhiên, quá trình này đòi hỏi tài nguyên tính toán lớn và thời gian xử lý mỗi hình ảnh có thể lên đến 5 giây, thường cần gọi lại mạng nơ-ron lớn từ 20 đến 40 lần. Điều này đặt ra giới hạn cho các ứng dụng yêu cầu tạo hình ảnh nhanh chóng và thực thời.
Chúng tôi đã vượt qua rào cản này bằng cách áp dụng công nghệ mới – Phân phối đối kháng tiến bộ (Progressive Adversarial Distillation). Phương pháp này giúp SDXL-Lightning tạo ra hình ảnh chất lượng cao trong chỉ 2 hoặc 4 bước, giảm đáng kể chi phí tính toán và thời gian so với các phương pháp truyền thống. Thậm chí, trong một số trường hợp, mô hình có thể tạo ra hình ảnh trong 1 bước, mặc dù chất lượng có thể giảm đôi chút.
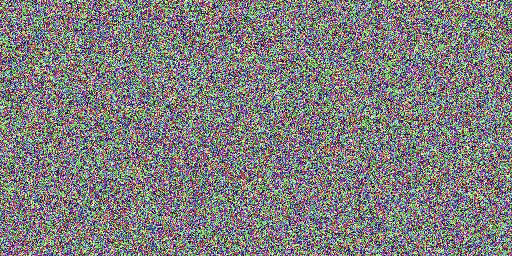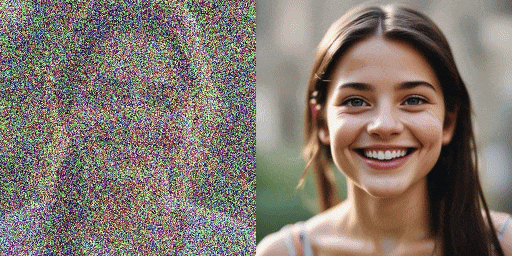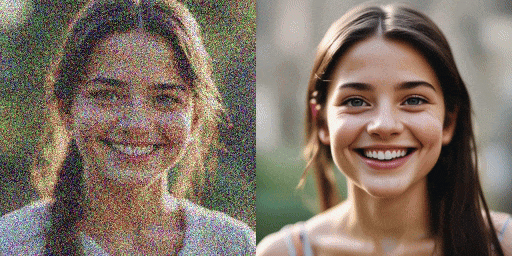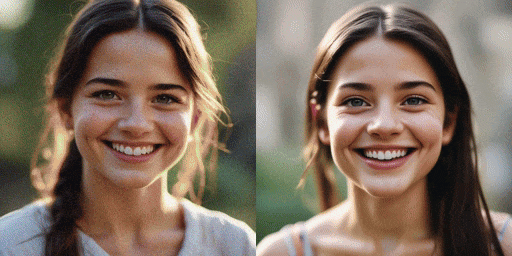
Đối với mô hình gốc cần 20 bước, SDXL-Lightning chỉ cần 2 hoặc 4 bước để tạo ra hình ảnh chất lượng cao. Số bước càng nhiều, chất lượng hình ảnh càng tốt.

Sự mở cửa và chia sẻ nguồn lực đã trở thành động lực mạnh mẽ thúc đẩy sự phát triển của AI. ByteDance tự hào là một phần của làn sóng này. Mô hình của chúng tôi dựa trên mô hình tạo hình ảnh văn bản SDXL phổ biến nhất hiện nay, và đã tạo nên một hệ sinh thái sôi động. Bây giờ, chúng tôi quyết định mở rộng mô hình SDXL-Lightning cho tất cả các nhà phát triển, nhà nghiên cứu và người sáng tạo trên toàn thế giới, để họ có thể tiếp cận và sử dụng nó, góp phần thúc đẩy sự đổi mới và hợp tác trong ngành.



Từ góc độ lý thuyết, quá trình tạo hình ảnh là một quá trình chuyển đổi từ nhiễu thành hình ảnh rõ ràng. Trong quá trình này, mạng nơ-ron học các hướng dẫn tại các vị trí khác nhau trong dòng chuyển đổi.
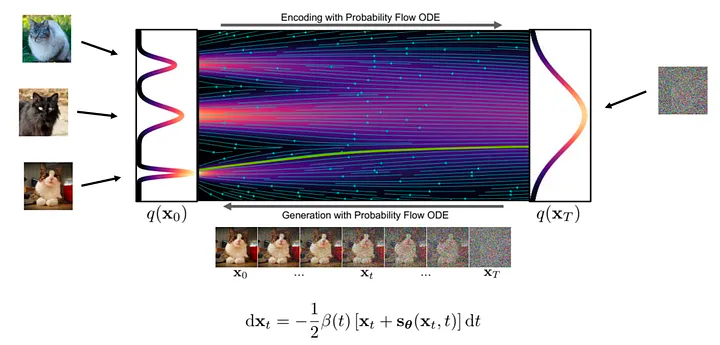
Hình: Quá trình tạo hình ảnh (nguồn: https://arxiv.org/abs/2011.13456)
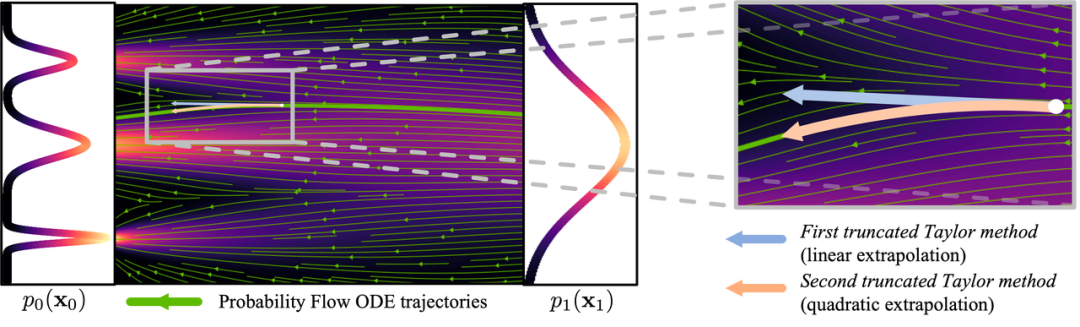
Hình: Dòng chảy (ảnh từ: https://arxiv.org/abs/2210.05475)
Để giảm số lượng bước cần thiết để tạo hình ảnh, nhiều nghiên cứu đã tập trung vào việc tìm giải pháp. Một số đề xuất phương pháp lấy mẫu giảm thiểu lỗi, trong khi những nghiên cứu khác cố gắng làm cho dòng chảy tạo hình ảnh trở nên trực tiếp hơn. Mặc dù những phương pháp này đã đạt được tiến bộ, chúng vẫn cần hơn 10 bước để tạo ra hình ảnh.
Một phương pháp khác là phân phối đối kháng, cho phép tạo ra hình ảnh chất lượng cao trong ít hơn 10 bước. Thay vì tính toán hướng dẫn tại vị trí hiện tại, phương pháp phân phối đối kháng thay đổi mục tiêu dự đoán của mạng, để nó dự đoán vị trí trong tương lai. Cụ thể, chúng tôi huấn luyện một mạng học sinh để dự đoán kết quả mà mạng giáo viên sẽ tạo ra sau nhiều bước suy luận. Chiến lược này giúp giảm đáng kể số lượng bước cần thiết. Quá trình này có thể được lặp đi lặp lại để giảm thêm số lượng bước.
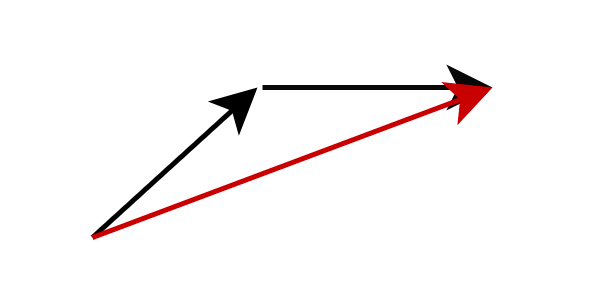
Hình: Phân phối đối kháng, mạng học sinh dự đoán kết quả của mạng giáo viên sau nhiều bước
Trong thực tế, mạng học sinh thường khó dự đoán chính xác vị trí trong tương lai. Sai số tích lũy theo mỗi bước, dẫn đến hình ảnh mờ đi khi tạo ra trong ít hơn 8 bước.
Để giải quyết vấn đề này, chiến lược của chúng tôi không yêu cầu mạng học sinh dự đoán chính xác như mạng giáo viên, mà thay vào đó, mạng học sinh được huấn luyện để dự đoán một vị trí có thể xảy ra. Ngay cả khi vị trí này không hoàn toàn chính xác, chúng tôi cũng không phạt nó. Mục tiêu này được thực hiện thông qua huấn luyện đối kháng, với sự hỗ trợ của mạng phân biệt bổ sung giúp mạng học sinh và mạng giáo viên tạo ra phân phối đầu ra tương đồng.
Đây là một cái nhìn tổng quan về phương pháp nghiên cứu của chúng tôi. Trong bài báo khoa học (https://arxiv.org/abs/2402.13929), chúng tôi cung cấp phân tích lý thuyết sâu hơn, chiến lược huấn luyện và chi tiết hóa cụ thể của mô hình.
Mặc dù nghiên cứu này chủ yếu tập trung vào việc sử dụng công nghệ SDXL-Lightning để tạo hình ảnh, nhưng phương pháp phân phối đối kháng tiến bộ mà chúng tôi đề xuất có tiềm năng ứng dụng không giới hạn ở lĩnh vực tạo hình ảnh tĩnh. Công nghệ sáng tạo này cũng có thể được sử dụng để tạo video, âm thanh và nội dung đa phương tiện khác một cách nhanh chóng và chất lượng cao. Chúng tôi rất mong muốn bạn thử nghiệm SDXL-Lightning trên nền tảng HuggingFace và chia sẻ phản hồi quý giá của bạn.
Những tin tức nổi bật khác về AI tuần này bao gồm: Li Yizhou bị phanh phui hoặc gây ảnh hưởng đến ngành học máy móc; đồng sáng lập Google bị cáo buộc tội ngộ sát; Huang Renxun tăng tài sản lên vị trí thứ 21 toàn cầu, khen ngợi Huawei; Alibaba bắt chước lịch làm việc của Sora?
Yangqing Jia nghi ngờ tuyên bố của CEO Groq về việc “giá chip gần như miễn phí”, cựu nhân viên ra mặt chứng minh: hoàn toàn không thực tế!
Từ khóa:
- SDXL-Lightning
- Trí tuệ nhân tạo
- Phân phối đối kháng
- Mạng học sinh
- Nhà phát triển
© Thông báo bản quyền
Bản quyền bài viết thuộc về tác giả, vui lòng không sao chép khi chưa được phép.
Những bài viết liên quan:




Không có đánh giá...