
Yi-VL, mô hình ngôn ngữ đa mô thức do Zero One phát hành và mã nguồn mở, đánh giá chỉ sau GPT-4V.
Zero One Wanshi Raids vào Thị Trường Máy Tính Đa Mô Hình với Yi-VL
Vào ngày 22 tháng 1, công ty Zero One Wanshi đã ra mắt mô hình ngôn ngữ đa mô hình Yi Vision Language (Yi-VL) và chính thức mở cửa cho cộng đồng toàn cầu. Yi-VL dựa trên mô hình ngôn ngữ Yi và bao gồm hai phiên bản là Yi-VL-34B và Yi-VL-6B.
Theo thông tin từ Zero One Wanshi, Yi-VL đã đạt được thành tích nổi bật trên bộ dữ liệu MMMU tiếng Anh và CMMMU tiếng Trung. Bộ dữ liệu MMMU (Massive Multi-discipline Multi-modal Understanding & Reasoning) bao gồm hơn 11.500 câu hỏi từ sáu lĩnh vực khoa học chính (nghệ thuật và thiết kế, kinh doanh, khoa học, sức khỏe và y tế, nhân văn và xã hội học, cũng như kỹ thuật và công nghệ). Bộ dữ liệu này đòi hỏi khả năng nhận biết và suy luận phức tạp đối với mô hình.

Mô hình Yi-VL-34B đã đạt được tỷ lệ chính xác 41.6% trên tập kiểm tra này, chỉ sau GPT-4V (55.7%).
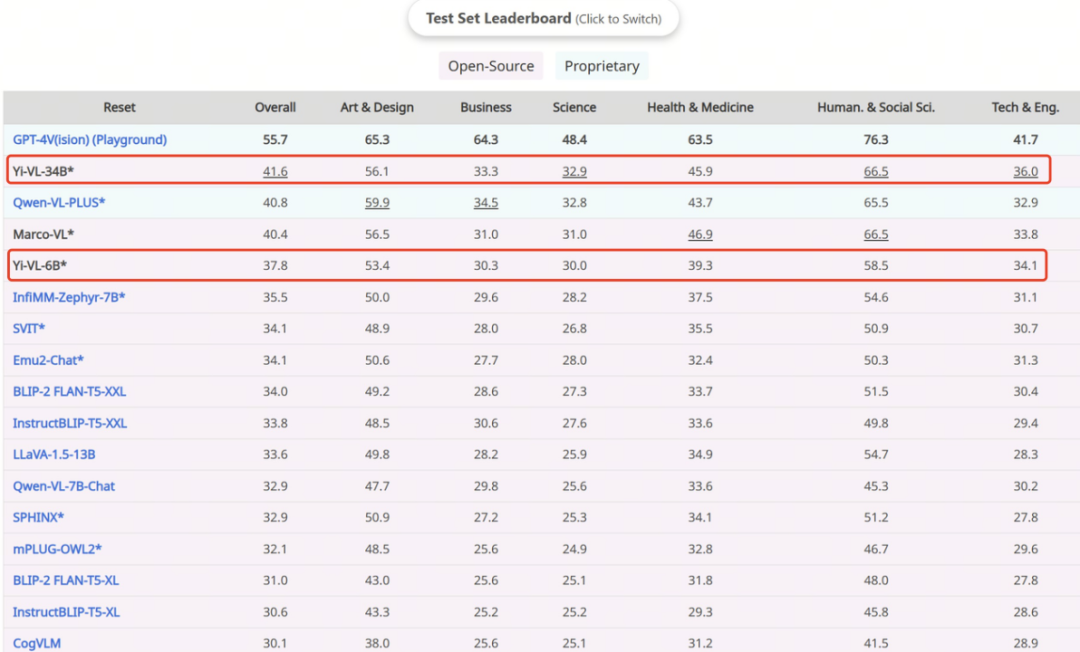
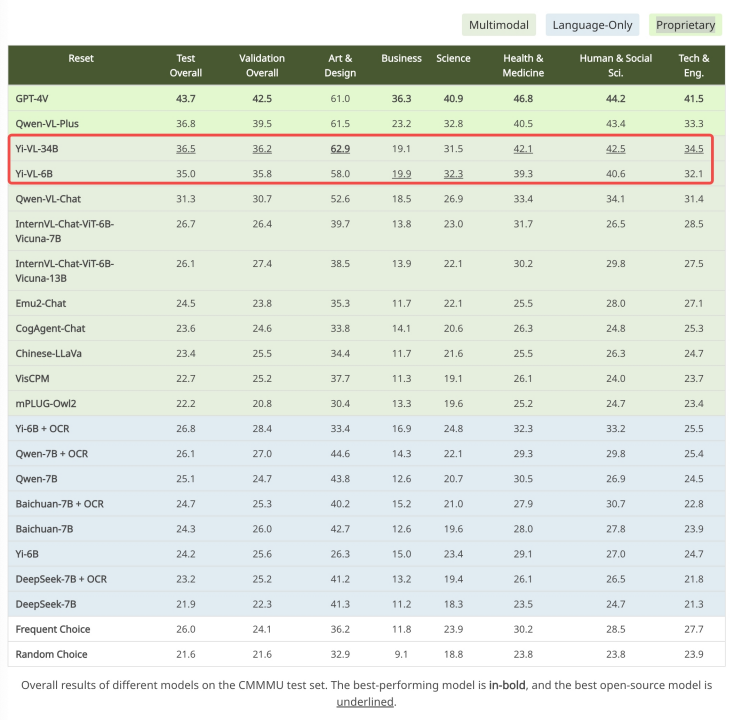
Tương tự, trên bộ dữ liệu CMMMU được thiết kế dành riêng cho ngữ cảnh tiếng Trung, Yi-VL tiếp tục thể hiện ưu thế của mình. CMMMU bao gồm khoảng 12.000 câu hỏi từ các kỳ thi đại học, bài kiểm tra và sách giáo trình tiếng Trung. Trong đó, GPT-4V đạt tỷ lệ chính xác 43.7%, còn Yi-VL-34B đạt 36.5%.


Yi-VL thể hiện hiệu suất mạnh mẽ trong các kịch bản đa dạng như cuộc trò chuyện hình ảnh và văn bản. Ví dụ, dựa trên khả năng hiểu văn bản mạnh mẽ của mô hình ngôn ngữ Yi, việc đối chiếu hình ảnh có thể tạo ra một mô hình ngôn ngữ đa mô hình hiệu quả.


Trong cấu trúc kiến trúc, Yi-VL dựa trên cấu trúc LLaVA mở nguồn, bao gồm ba module chính:
- Vision Transformer (ViT): Được sử dụng để mã hóa hình ảnh, được khởi tạo với tham số có thể huấn luyện từ mô hình OpenClip ViT-H/14.
- Projection: Module này giúp hòa quyện không gian đặc trưng hình ảnh và văn bản, tăng cường khả năng hiểu và xử lý thông tin đa mô hình.
- Yi-34B-Chat và Yi-6B-Chat: Mô hình ngôn ngữ lớn giúp Yi-VL hiểu và tạo ra văn bản liên quan và mạch lạc.
Quá trình huấn luyện Yi-VL chia thành ba giai đoạn:
- Giai đoạn 1: Sử dụng 100 triệu cặp dữ liệu “hình ảnh – văn bản” để huấn luyện ViT và module Projection.
- Giai đoạn 2: Nâng cấp độ phân giải hình ảnh lên 448×448 để cải thiện khả năng nhận biết chi tiết hình ảnh.
- Giai đoạn 3: Mở rộng toàn bộ tham số mô hình để cải thiện hiệu suất trong các tương tác đa mô hình.
Cộng đồng có thể trải nghiệm Yi-VL tại các nền tảng như Hugging Face và ModelScope.
Hiện tại, đội ngũ phát triển Yi-VL đang tiếp tục nghiên cứu và khám phá các phương pháp mới để nâng cao hiệu suất và đạt được vị trí hàng đầu thế giới.
Tóm tắt 5 từ khóa:
- Yi-VL
- Mô hình Ngôn ngữ Đa mô hình
- Zero One Wanshi
- Hugging Face
- ModelScope
© Thông báo bản quyền
Bản quyền bài viết thuộc về tác giả, vui lòng không sao chép khi chưa được phép.
Những bài viết liên quan:




Không có đánh giá...