
HTAP hỗ trợ phân tích thời gian giao hàng trong ngành vận chuyển.
Hiệu suất và hiệu quả trong ngành vận chuyển hàng hóa bằng đường bưu điện
Ngành thương mại điện tử đang trở thành một phần không thể thiếu trong cuộc sống hàng ngày của mọi người. Cùng với sự phát triển nhanh chóng của ngành, lượng hàng hóa được vận chuyển cũng tăng lên đáng kể. Do đó, việc tối ưu hóa thời gian vận chuyển đã trở thành một vấn đề cấp bách mà các công ty vận chuyển phải đối mặt. Liệu có cách nào để vừa giảm chi phí lại vừa cải thiện hiệu suất?
Toàn bộ chu kỳ vận chuyển hàng hóa có thể được tóm tắt bằng năm từ: nhận, gửi, đến, phân phối và ký nhận. “Nhận” bao gồm việc khách hàng đặt hàng, nhân viên giao hàng đến thu gom hàng hóa, và các điểm giao dịch đóng gói hàng. “Gửi” đề cập đến việc hàng hóa được vận chuyển từ trung tâm vận chuyển đến điểm đến. “Đến” là khi hàng hóa đến điểm cuối cùng và được phân loại tại các điểm giao dịch. “Phân phối” là quá trình phân loại hàng hóa tại điểm giao dịch và bắt đầu việc giao hàng bởi nhân viên giao hàng. Cuối cùng, “ký nhận” là khi khách hàng ký nhận hàng sau khi nhận từ nhân viên giao hàng.
Công ty ZTO Express đã phát triển một nền tảng dữ liệu lớn mạnh tự nghiên cứu (xem Hình 2-3-1), hỗ trợ mô hình dữ liệu ETL (trích xuất, biến đổi, tải) đến mức độ nửa giờ. Nền tảng dữ liệu lớn của ZTO Express hỗ trợ việc tiếp nhận nhiều nguồn dữ liệu khác nhau như cơ sở dữ liệu quan hệ MySQL, Oracle, cơ sở dữ liệu tài liệu MongoDB và Elasticsearch (ES). Cơ bản, tất cả các tác vụ thực thi ngay lập tức đều được quản lý thông qua nền tảng dữ liệu lớn này, hỗ trợ việc tiếp nhận Kafka, hàng đợi tin nhắn (MQ) và nhiều hơn nữa. Dù là tác vụ ETL ngoại tuyến hay tác vụ thực thi ngay lập tức của Spark/Flink, chúng đều được tiếp nhận vào cụm tính toán dữ liệu lớn thông qua nền tảng dữ liệu lớn này và cuối cùng được tính toán. Kết quả tính toán sau đó được cung cấp cho người dùng thông qua nền tảng dữ liệu lớn: hoặc đẩy dữ liệu đến ứng dụng dữ liệu, dùng cho phân tích và báo cáo; hoặc cung cấp cho engine tra cứu OLAP, cho phép người dùng hoặc hệ thống khác tra cứu.
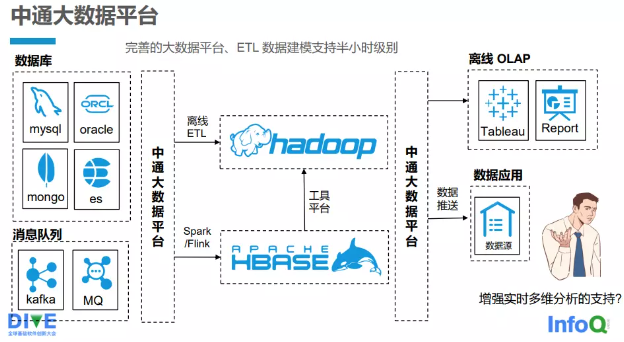
Nền tảng dữ liệu lớn cần đáp ứng nhu cầu kinh doanh. Các đặc điểm kinh doanh của ZTO Express bao gồm:
- Lượng lớn: Kinh doanh phát triển nhanh chóng, lượng dữ liệu lớn, và mỗi đơn đặt hàng có thể có từ 5 đến 6 lần cập nhật, thậm chí nhiều hơn.
- Kỳ hạn phân tích dài: Yêu cầu phân tích dữ liệu ngày càng dài hơn.
- Yêu cầu về thời gian nhanh: Yêu cầu về thời gian phân tích cũng ngày càng cao, không còn hài lòng với việc tính toán ngoại tuyến T+1 hoặc phân tích ở mức độ nửa giờ.
- Nhiều chiều: Phương án kỹ thuật hỗ trợ phân tích linh hoạt đa chiều.
- Yêu cầu khả dụng cao: Cần vượt qua giới hạn hiệu suất đơn máy, lỗi đơn điểm, và rút ngắn hoặc loại bỏ thời gian phục hồi lỗi.
- Nhiều yêu cầu đồng thời: QPS (số yêu cầu mỗi giây) cao, yêu cầu ứng dụng đạt đến mức phản hồi mili giây.
Từ góc độ kỹ thuật, cần thực hiện:
- Kết nối nhiều kịch bản kinh doanh, thiết lập nhiều chỉ số kinh doanh.
- Thực hiện giao dịch phân tán nhất quán mạnh mẽ, chuyển đổi mô hình kinh doanh cũ ít tốn kém.
- Tính toán và lưu trữ quy trình hóa, lưu trữ ngoại tuyến.
- Hỗ trợ viết và cập nhật đồng thời cao.
- Hỗ trợ chỉ mục cấp 2 và truy vấn đồng thời cao.
- Hỗ trợ bảo trì trực tuyến, lỗi đơn điểm không ảnh hưởng đến kinh doanh.
- Hỗ trợ điều chỉnh nóng.
- Đặt sâu vào sinh thái công nghệ hiện tại, đạt được phân tích thống kê phút.
- Hỗ trợ bảng rộng với hơn 100 cột, hỗ trợ phân tích và truy vấn đa chiều.
Dựa trên nhu cầu kinh doanh và kỹ thuật trên, ZTO Express đã áp dụng TiDB, đưa nhiều dòng kinh doanh lên TiDB, bao gồm trung tâm dữ liệu, bảng rộng thực, phân tích thời gian thực, bảng theo dõi đại hội.
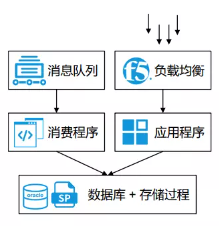
Hệ thống thời gian thực của ZTO Express là một sự tái cấu trúc của hệ thống thời gian thực ban đầu. Cấu trúc tổng thể của hệ thống thời gian thực ban đầu (xem Hình 2-3-2) tương đối đơn giản, hàng đợi tiêu thụ thông qua chương trình tin nhắn viết tất cả dữ liệu vào cơ sở dữ liệu, cuối cùng tạo ra nhiều thủ tục lưu trữ trên cơ sở dữ liệu để phân tích dữ liệu, và cuối cùng cung cấp kết quả phân tích cho ứng dụng để truy vấn.
Cấu trúc hệ thống thời gian thực được nâng cấp (xem Hình 2-3-3) đã giới thiệu TiDB và TiSpark, tiếp nhận tin nhắn bằng Spark/Flink, và cuối cùng dữ liệu được ghi vào TiDB. Tất cả thủ tục lưu trữ ban đầu đã bị hủy bỏ và thay thế bằng TiSpark. Dữ liệu sẽ được ghi vào hai nơi: dữ liệu tổng hợp nhẹ được ghi trực tiếp vào Hive (một công cụ kho dữ liệu của Hadoop), thông qua OLAP cung cấp dịch vụ truy vấn; dữ liệu tổng hợp giữa chừng, được ghi trực tiếp vào cơ sở dữ liệu quan hệ, như MySQL. Ngoài ra, mỗi ngày sử dụng DataX đồng bộ dữ liệu T+1 từ cơ sở dữ liệu TiDB sang Hive, để thực hiện tác vụ ETL ngoại tuyến vào ngày hôm sau.
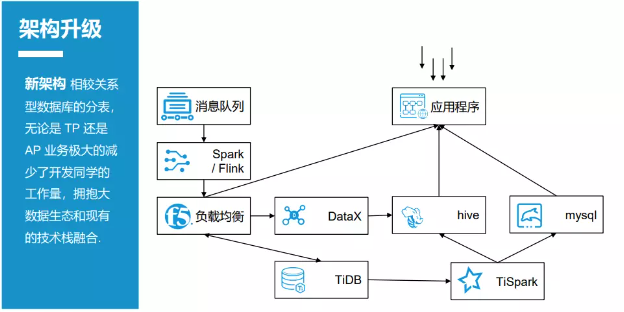
Việc nâng cấp cấu trúc hệ thống thời gian thực mang lại nhiều lợi ích.
- Chu kỳ lưu trữ dữ liệu của hệ thống hiện tại đã tăng từ 15 ngày lên 45 ngày, và sẽ tăng lên 60 ngày, và thậm chí có thể lâu hơn. Về khả năng mở rộng, cấu trúc được nâng cấp có thể hỗ trợ mở rộng ngang trực tuyến, dễ dàng thêm hoặc loại bỏ các nút lưu trữ và tính toán, và ứng dụng gần như không nhận thức được điều này.
- Về khả năng xử lý đồng thời, cấu trúc được nâng cấp có thể đáp ứng nhu cầu kinh doanh OLTP có hiệu suất cao, tốc độ truy vấn thấp hơn so với hệ thống ban đầu, nhưng vẫn đáp ứng nhu cầu.
- Áp lực của điểm đơn trên cơ sở dữ liệu đã được giải quyết, thực hiện “phân tách” giữa TP và AP, và thực hiện cách ly tài nguyên.
- Hỗ trợ phân tích kinh doanh đa chiều, đáp ứng nhu cầu phân tích kinh doanh đa chiều.
Cấu trúc tổng thể rõ ràng hơn, khả năng bảo trì tăng lên, so với các thủ tục lưu trữ trước đây, toàn bộ cấu trúc sau khi nâng cấp rất rõ ràng.
Bây giờ, chúng tôi sẽ giới thiệu ngắn gọn về việc xây dựng bảng rộng của ZTO Express, như Hình 2-3-4 cho thấy.
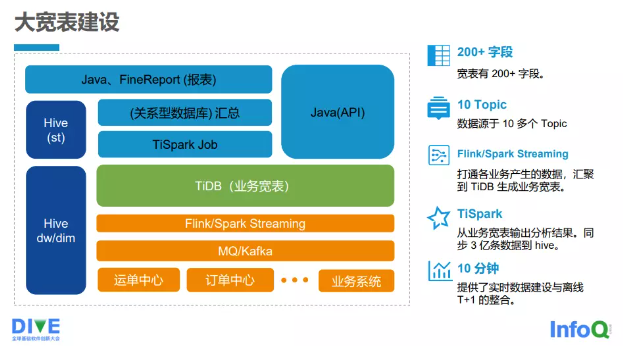
- Bảng rộng hiện có hơn 200 trường, và vẫn đang tiếp tục tăng.
- Đã tiếp nhận dữ liệu từ hơn 10 chủ đề (Topic).
- Đã kết nối dữ liệu từ các nguồn kinh doanh khác nhau và tập hợp vào TiDB để tạo bảng kinh doanh rộng, sử dụng hệ thống xử lý luồng Flink/Spark Streaming để ghi dữ liệu cuối cùng vào bảng rộng TiDB.
- Sử dụng TiSpark, phân tích dữ liệu từ bảng kinh doanh rộng và đồng bộ hơn 300 triệu dữ liệu vào Hive.
- Cung cấp xây dựng dữ liệu thực và tích hợp dữ liệu ngoại tuyến T+1, cơ bản hoàn thành trong 10 phút.
Các điểm tiếp cận, như trung tâm vận đơn, trung tâm đơn đặt hàng và các hệ thống kinh doanh khác, sẽ ghi dữ liệu vào MQ/Kafka. Flink/Spark Streaming sẽ ghi tin nhắn từ Kafka vào bảng rộng TiDB (TDB). Trên bảng rộng TiDB là TiSpark, nó sẽ thông qua xử lý lô của TiSpark cuối cùng ghi dữ liệu vào lớp DW hoặc DIM, và cũng ghi một số dữ liệu tổng hợp vào lớp ST, và dữ liệu tổng hợp dần dần ghi vào cơ sở dữ liệu quan hệ. Cuối cùng, ứng dụng Java hoặc báo cáo FineReport sẽ đọc dữ liệu tổng hợp từ cơ sở dữ liệu quan hệ và dữ liệu từ lớp ST.
Ngoài ra, bảng rộng cũng cung cấp nhiều dịch vụ API, các sản phẩm như trung tâm dữ liệu, hệ thống phân tích thời gian thực, hệ thống bảng theo dõi dữ liệu, v.v., đều sử dụng dữ liệu từ bảng rộng.
Khi sử dụng, chúng tôi cũng gặp nhiều vấn đề, tôi tóm tắt thành việc thay đổi chất lượng dẫn đến thay đổi về số lượng.
- Vấn đề nóng: Trong giai đoạn cao điểm kinh doanh, vấn đề nóng của chỉ mục khá nổi bật, nhiều nghiệp vụ dựa trên thời gian để truy vấn, việc ghi hoặc cập nhật liên tục trong các khoảng thời gian liên tục sẽ gây ra chỉ mục nóng. Điều này đặc biệt rõ ràng trong các đợt khuyến mãi lớn, điều này dẫn đến áp lực lớn đối với một số TiKV.
- Vấn đề phân mảnh bộ nhớ: Sau khi hệ thống chạy ổn định một thời gian, nhiều cập nhật và xóa sẽ dẫn đến phân mảnh bộ nhớ. Vấn đề này đã được sửa chữa trong phiên bản sau, và không có bất thường sau khi nâng cấp hệ thống.
- Vấn đề sử dụng tham số đúng: Khi lượng dữ liệu đọc đạt hơn 1/10 tổng lượng dữ liệu, nên tắt tham số tispark.plan.allow_index_read. Vì trong trường hợp này, lợi ích của tham số này sẽ trở nên rất nhỏ, thậm chí có thể gây ra một số tác động tiêu cực.
TiDB đã có nhiều chỉ số giám sát phong phú, nó sử dụng Prometheus + Grafana phổ biến hiện nay, chỉ số giám sát rất nhiều và đầy đủ. TiDB hỗ trợ doanh nghiệp trực tuyến và cũng hỗ trợ người phát triển truy vấn dữ liệu, do đó có thể gặp một số thao tác bất thường, thậm chí gặp một số câu lệnh SQL ảnh hưởng đến việc chạy máy chủ, ảnh hưởng đến sản xuất. Dựa trên chức năng giám sát của TiDB và một số vấn đề gặp phải trong quá trình sử dụng, chúng tôi đã xây dựng hệ thống giám sát và cảnh báo tự động, giám sát các câu lệnh truy vấn chậm của tài khoản trực tuyến đặc biệt, tự động “hủy” các câu lệnh bất thường và thông báo cho quản trị viên vận hành và người chịu trách nhiệm ứng dụng. Chúng tôi cũng đã phát triển nền tảng truy vấn cho phép người dùng sử dụng Spark SQL để truy vấn dữ liệu từ TiDB, cân nhắc cả khả năng xử lý đồng thời và an ninh. Đối với một số chỉ số quan trọng, chúng tôi đã tiếp cận tự động giám sát, truyền thông tin cảnh báo cốt lõi qua điện thoại cho các nhân viên trực ca liên quan.
Nhu cầu của khách hàng liên tục tăng lên, họ không chỉ mong muốn lưu trữ nhiều dữ liệu hơn, mà còn mong muốn hệ thống hoạt động nhanh hơn. Họ không chỉ mong muốn hệ thống đáp ứng chu kỳ phân tích dữ liệu ngày càng dài, mà còn mong muốn nhận biết thay đổi kinh doanh nhanh hơn. Hệ thống phụ thuộc cần nhiều thông tin đăng ký hơn, mong muốn chủ động điều chỉnh khi thông tin không đáp ứng nhu cầu. Trong khi tổ chức các sự kiện khuyến mãi lớn, áp lực đối với TiKV rất lớn, chúng tôi cần thực sự tách rời tính toán và lưu trữ. Hệ thống lớn quá, khó quản lý, khó khăn trong việc khắc phục sự cố. Do đó, chúng tôi đã nâng cấp cấu trúc một lần nữa, cấu trúc được nâng cấp lần thứ hai như Hình 2-3-5 cho thấy.
Trong kỷ nguyên 2.0, chúng tôi đã giới thiệu TiFlash và TiCDC. Tại sao chúng tôi giới thiệu TiFlash? Vì TiFlash là một cơ sở dữ liệu cột, khi tạo một chuỗi đồng bộ hóa trên TiDB, toàn bộ cấu trúc bao gồm cả TiDB không cần phải thay đổi. Toàn bộ cấu trúc ghi dữ liệu là không thay đổi, vẫn có thể ghi dữ liệu vào bảng rộng TiDB thông qua Flink/Spark. Mặc dù chúng tôi đã giới thiệu TiFlash, nhưng vẫn giữ một số tác vụ TiSpark. Do đặc điểm kinh doanh, kết quả dữ liệu được tổng hợp từ một số dữ liệu có thể đạt đến hàng triệu hoặc hàng triệu, tất cả đều được ghi vào TiDB thông qua TiFlash, hiệu suất thời gian không theo kịp. TiDB đã cung cấp giải pháp sau đó cho nhu cầu này, tính toán dữ liệu sẽ được chuyển một phần sang TiFlash, TiSpark và TiFlash cùng tồn tại. Dữ liệu tổng hợp của TiSpark hoặc TiSpark vẫn sẽ được ghi vào Hive, một phần cũng sẽ được ghi vào MySQL, và cả hai đều cung cấp dịch vụ dữ liệu. Chúng tôi đã giới thiệu TiCDC để đồng bộ Biglog của TiDB vào hàng đợi tin nhắn, để sử dụng bởi các doanh nghiệp phụ thuộc, thực hiện tiêu thụ khu vực.
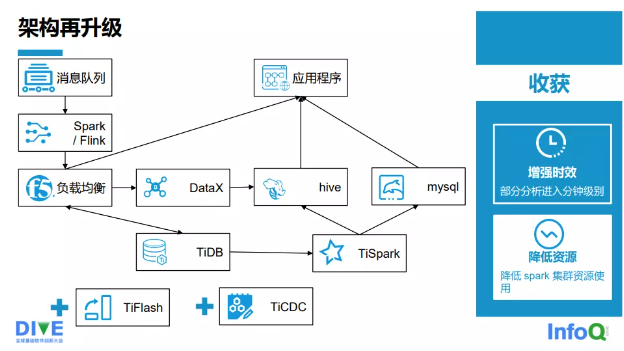
Có hai lợi ích từ việc nâng cấp cấu trúc:
- Giảm thời gian chờ đợi, một số phân tích đã bước vào giai đoạn phút, khoảng cách chạy từ 5-15 phút giảm xuống còn 1-2 phút.
- Giảm sử dụng tài nguyên, giảm lượng tài nguyên cần thiết cho cụm Spark, vật lý nút từ khoảng 137 giảm xuống còn 77.
Tương lai, chúng tôi vẫn còn nhiều vấn đề cần giải quyết, và nhiều lĩnh vực cần cải thiện hơn nữa.
- Giám sát luôn là một vấn đề khó khăn – quy mô cụm của chúng tôi lớn, chỉ số nhiều, và đôi khi tải rất chậm, hiệu suất khắc phục sự cố không được đảm bảo. Mặc dù giám sát đầy đủ, nhưng khi xảy ra vấn đề, chúng tôi không thể xác định nhanh chóng, điều này cũng gây ra một số khó khăn cho chúng tôi khi khắc phục sự cố trực tuyến.
- Chương trình thực thi ngẫu nhiên không chính xác, ảnh hưởng đến chỉ số cụm, gây ra sự ảnh hưởng lẫn nhau giữa các nghiệp vụ. Tình huống này có thể liên quan đến thông tin thống kê bảng. Việc làm sạch dữ liệu trong quá khứ vẫn khá phức tạp, hiện tại chúng tôi sử dụng các script tự viết để hỗ trợ chức năng tự động TTL (thời gian sống) cho dữ liệu cũ. Mặc dù TiFlash hiện đã hỗ trợ nhiều hàm, nhưng chúng tôi hy vọng có thể hỗ trợ thêm nhiều hàm khác trong ứng dụng.
- Nâng cao độ ổn định của cụm.
- Triển khai hỗ trợ TiSpark đối với Batch TiFlash.
- Hỗ trợ cách ly người dùng và tài nguyên, tránh ảnh hưởng lẫn nhau.
- Triển khai hỗ trợ bảng phân vùng, lọc dữ liệu, tăng cường hiệu suất tính toán.
- Giảm thiểu rung động tính toán.
Chu Yizhi: Kiến trúc sư dữ liệu lớn của ZTO Express, chịu trách nhiệm về cơ sở hạ tầng dữ liệu cơ bản của ZTO Express.
Với sự phát triển của điện toán đám mây và trí tuệ nhân tạo, ngăn xếp công nghệ cơ bản cũng đang thay đổi. Hiện tại, sách về lĩnh vực phần mềm cơ bản còn hạn chế, và hầu hết đều không được cập nhật trong hai năm gần đây. Tuy nhiên, lĩnh vực phần mềm cơ bản đã thay đổi đáng kể. Phần mềm cơ bản mà chúng tôi thảo luận hiện tại là phần mềm dựa trên đám mây và trí tuệ nhân tạo, những thay đổi mới này đều có thể tìm thấy câu trả lời trong cuốn sách này.

Từ khóa:
- Hệ thống phân tích thời gian thực
- Nền tảng dữ liệu lớn
- Chu kỳ phân tích
- Chuỗi đồng bộ hóa
- TiDB
© Thông báo bản quyền
Bản quyền bài viết thuộc về tác giả, vui lòng không sao chép khi chưa được phép.
Những bài viết liên quan:




Không có đánh giá...