
Đại học Tsinghua và Zhiyuan AI hợp tác ra mắt CogAgent: Agent GUI dựa trên mô hình lớn đa mô thức, có khả năng hỏi đáp hình ảnh và định vị hình ảnh.

Mới đây, Phòng thí nghiệm KEK thuộc Đại học Thanh Hoa và Công ty Trí tuệ Zhipu đã cùng nhau ra mắt CogAgent – một mô hình hiểu thị giác chung. CogAgent có khả năng thực hiện nhiều tác vụ như hiểu thị giác, trả lời câu hỏi thị giác, định vị (Grounding), và là một đại diện của người máy giao diện người dùng (GUI Agent). Mô hình này có thể xử lý hình ảnh với độ phân giải cao lên đến 1120×1120. Trên chín bảng xếp hạng hiểu thị giác phổ biến (bao gồm VQAv2, STVQA, DocVQA, TextVQA, MM-VET, POPE, v.v.), CogAgent đã đạt được thành tích hàng đầu về khả năng tổng hợp. Đồng thời, trên bộ dữ liệu GUI Agent bao gồm cả máy tính và điện thoại di động (bao gồm Mind2Web, AITW, v.v.), CogAgent đã vượt trội hơn so với các đại diện dựa trên mô hình ngôn ngữ lớn (LLM) và đạt vị trí số một.
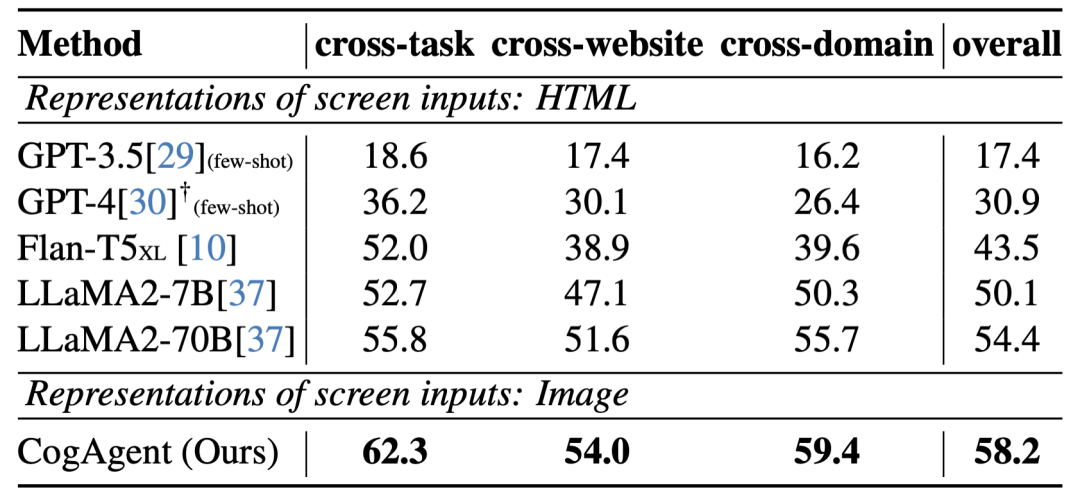
Trên bộ dữ liệu Mind2Web dành cho người máy trên trang web, hiệu suất của CogAgent
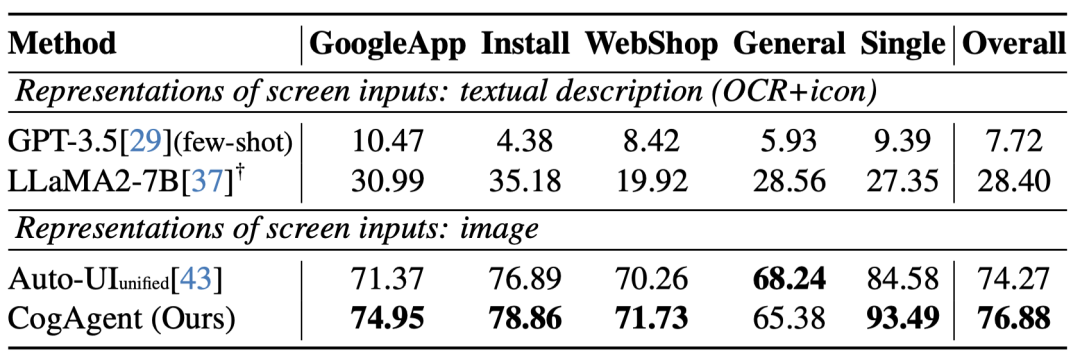
Hiệu suất của CogAgent trên bộ dữ liệu AITW dành cho người máy trên thiết bị di động
Để thúc đẩy sự phát triển của cộng đồng mô hình đa mô thức lớn và đại diện của người máy, nhóm nghiên cứu đã công khai mã nguồn của CogAgent-18B trên kho lưu trữ GitHub và cung cấp một phiên bản demo trực tuyến.
Liên kết bài báo: https://arxiv.org/pdf/2312.08914.pdf
Địa chỉ dự án GitHub (bao gồm mô hình mã nguồn mở và phiên bản demo trực tuyến): https://github.com/THUDM/CogVLM
Các đại diện dựa trên mô hình ngôn ngữ lớn (LLM) hiện đang là chủ đề nghiên cứu sôi nổi, với tiềm năng ứng dụng rộng lớn. Tuy nhiên, do hạn chế về mô thức của LLM, chúng chỉ có thể tiếp nhận dữ liệu dưới dạng văn bản. Ví dụ, trong trường hợp của người máy web, WebAgent và các công trình tương tự sẽ sử dụng HTML của trang web cùng với mục tiêu của người dùng (ví dụ: “Bạn có thể tìm kiếm CogAgent trên Google không?”) làm đầu vào cho LLM, từ đó thu được dự đoán hành động tiếp theo của LLM (ví dụ: nhấp chuột, nhập văn bản).
Tuy nhiên, một quan sát thú vị là con người tương tác với GUI thông qua thị giác. Ví dụ, khi được đưa ra một mục tiêu thao tác, con người sẽ quan sát giao diện GUI trước khi quyết định hành động tiếp theo; đồng thời, GUI được thiết kế đặc biệt để tương tác giữa người và máy, so với các biểu diễn dưới dạng văn bản như HTML, GUI dễ dàng hơn trong việc lấy thông tin hiệu quả. Điều này có nghĩa là trong bối cảnh GUI, thị giác là một mô thức giao tiếp trực tiếp và cơ bản hơn, cung cấp thông tin môi trường một cách hiệu quả và toàn diện hơn. Hơn nữa, nhiều giao diện GUI không có mã nguồn tương ứng và khó có thể diễn đạt bằng ngôn ngữ. Do đó, nếu có thể cải tiến mô hình lớn thành một đại diện thị giác, trực tiếp đưa vào mô hình lớn để hiểu, lập kế hoạch và ra quyết định thông qua hình ảnh GUI, đây sẽ là một phương pháp trực tiếp và hiệu quả hơn, với tiềm năng cải thiện đáng kể.
CogAgent có thể thực hiện một đại diện người máy dựa trên thị giác, với đường đi và khả năng như sau:
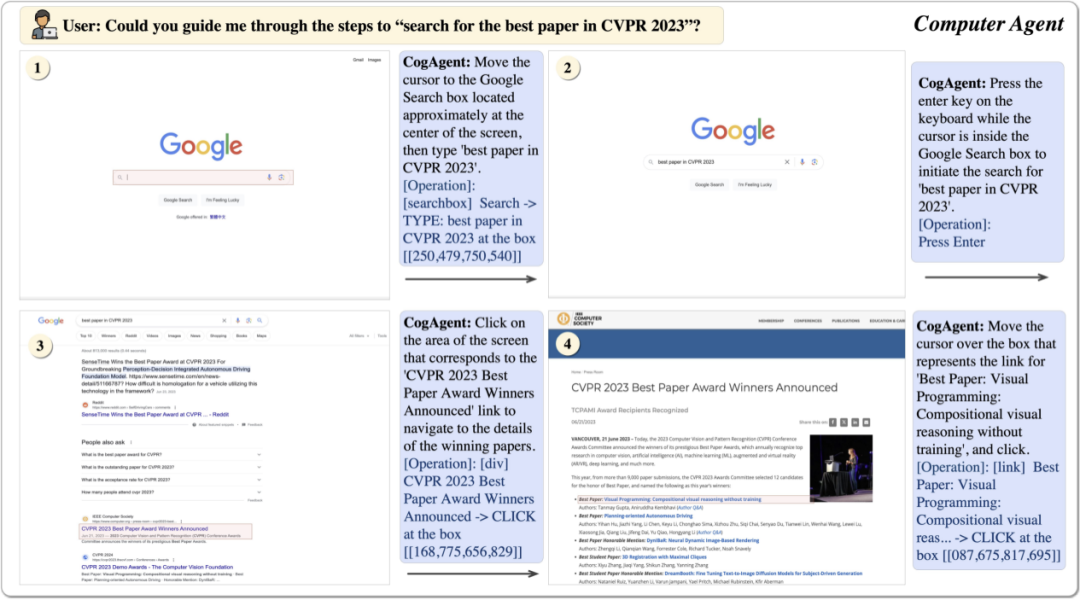
Mô hình CogAgent nhận đầu vào là ảnh chụp màn hình GUI hiện tại (dạng hình ảnh) và mục tiêu thao tác của người dùng (dạng văn bản, ví dụ: “tìm kiếm bài báo tốt nhất trong CVPR 2023”). Mô hình này sau đó dự đoán hành động chi tiết và tọa độ của phần tử thao tác tương ứng. Nó có thể áp dụng cho nhiều kịch bản, từ máy tính đến thiết bị di động. Nhờ khả năng tổng hợp của đại diện người máy GUI, CogAgent có thể đạt được hiệu suất tốt trong nhiều kịch bản và nhiệm vụ chưa từng thấy. Bài báo cũng trình bày thêm nhiều ví dụ, bao gồm cả PPT, hệ thống điện thoại di động, ứng dụng mạng xã hội, và trò chơi.
Theo giới thiệu, cấu trúc mô hình của CogAgent dựa trên CogVLM. Để giúp mô hình có khả năng hiểu hình ảnh độ phân giải cao, có thể nhìn thấy màn hình GUI 720p, nhóm đã tăng độ phân giải đầu vào hình ảnh lên 1120×1120 (so với các mô hình trước đây thường nhỏ hơn 500×500, bao gồm cả CogVLM, Qwen-VL, v.v.). Tuy nhiên, việc tăng độ phân giải này sẽ dẫn đến sự gia tăng đột ngột trong chuỗi hình ảnh, gây ra gánh nặng tính toán và bộ nhớ không thể chấp nhận được – đây cũng là một trong những lý do chính khiến nhiều mô hình tiền huấn luyện đa mô thức hiện tại thường sử dụng hình ảnh có độ phân giải thấp.
Đối với vấn đề này, nhóm đã thiết kế mô-đun chú ý chéo nhẹ nhàng, kết hợp một bộ mã hóa hình ảnh nhỏ độ phân giải cao (0,3 tỷ tham số) với bộ mã hóa hình ảnh lớn độ phân giải thấp (4,4 tỷ tham số) và sử dụng cơ chế chú ý chéo để tương tác với mô hình VLM ban đầu. Trong quá trình chú ý chéo, nhóm cũng đã sử dụng kích thước ẩn nhỏ hơn, giúp giảm bớt gánh nặng về bộ nhớ và tính toán.
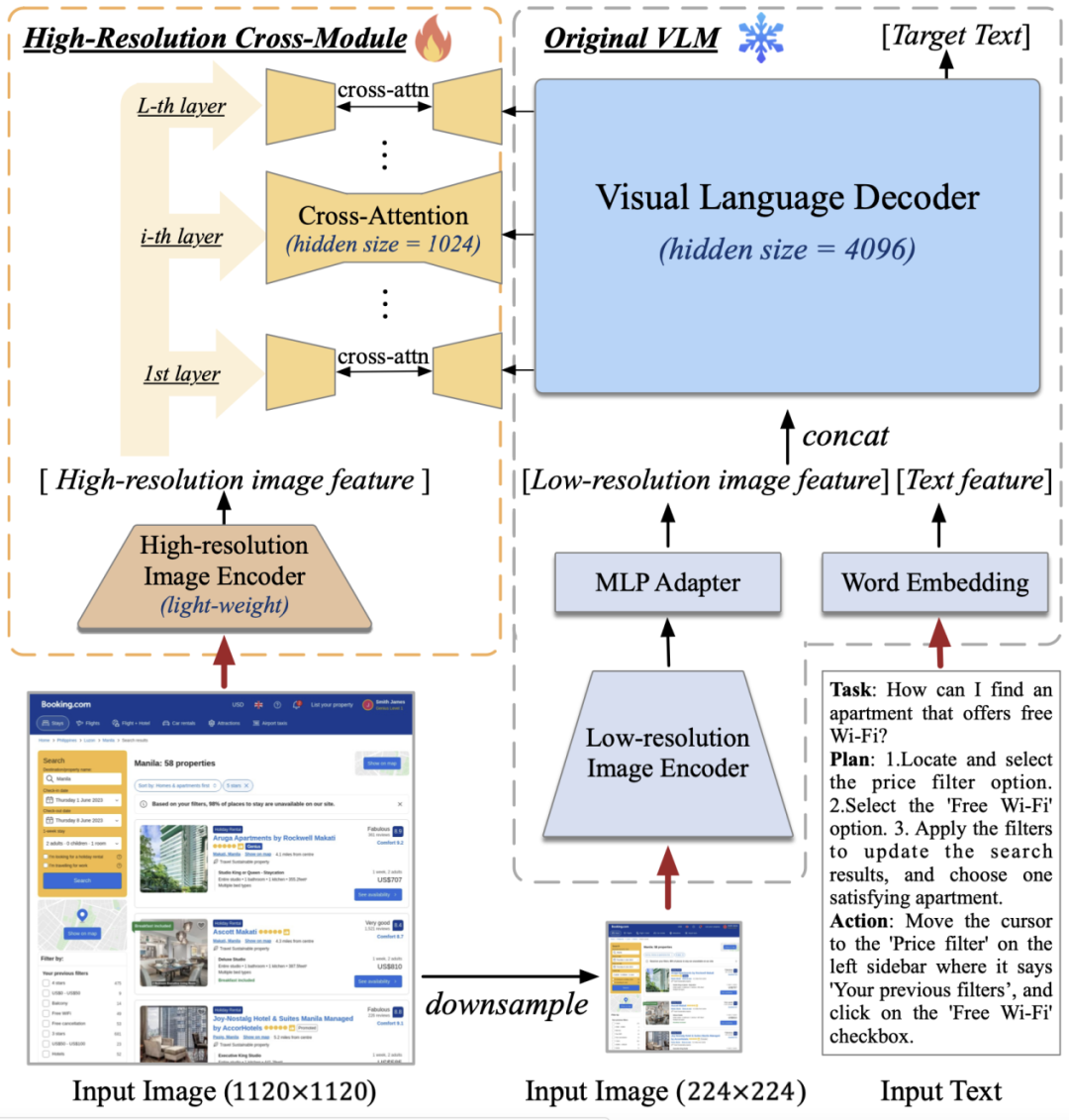
Kết quả cho thấy, phương pháp này giúp mô hình thành công trong việc hiểu hình ảnh độ phân giải cao và giảm đáng kể gánh nặng về bộ nhớ và tính toán. Trong các thí nghiệm loại trừ, nhóm cũng so sánh cấu trúc này với phương pháp ban đầu của CogVLM về mặt lượng tính toán. Kết quả cho thấy, khi độ phân giải tăng lên, phương pháp được trình bày trong bài báo (với mô-đun chú ý chéo, màu cam) chỉ tăng ít lượng tính toán và tỷ lệ thuận với sự tăng trưởng của chuỗi hình ảnh. Đặc biệt, mô hình CogAgent độ phân giải 1120×1120 thậm chí còn có lượng tính toán (FLOPs) nhỏ hơn một nửa so với mô hình CogVLM độ phân giải 490×490. Trong thử nghiệm suy luận INT4 trên một card đồ họa, mô hình CogAgent độ phân giải 1120×1120 chiếm khoảng 12,6GB bộ nhớ, chỉ cao hơn khoảng 2GB so với mô hình CogVLM độ phân giải 224×224.

Về dữ liệu, ngoài tập dữ liệu mô tả ảnh hình ảnh của CogVLM, nhóm đã mở rộng và tăng cường dữ liệu trong các lĩnh vực nhận dạng văn bản, định vị thị giác và hiểu hình ảnh GUI, từ đó cải thiện đáng kể hiệu suất trong các kịch bản người máy GUI. (Phương pháp thu thập và tạo dữ liệu huấn luyện và điều chỉnh trước của CogAgent được mô tả chi tiết trong phần 2.2 và 2.3 của bài báo.)
Bộ sưu tập các trường hợp chuyển đổi kỹ thuật số của Trung Quốc mang tên “Hành Trình Tri Thức Trung Quốc – Chuyển Đổi Số” phiên bản thứ hai đã được công bố, bao gồm nhiều ngành nghề và đối thoại với các chuyên gia hàng đầu, khám phá câu chuyện thực hành chuyển đổi số của doanh nghiệp, và tiết lộ cách doanh nghiệp có thể tái cấu trúc tổ chức, công nghệ và nhân lực trong bối cảnh kỷ nguyên kỹ thuật số. Quét mã QR bên dưới để theo dõi “InfoQ Digital Axis” và trả lời “Hành Trình Tri Thức Trung Quốc” để mở khóa toàn bộ nội dung.
### Từ khóa:
– Người máy GUI
– Hiểu thị giác
– CogAgent
– Trí tuệ nhân tạo
– Đại diện đa mô thức
© Thông báo bản quyền
Bản quyền bài viết thuộc về tác giả, vui lòng không sao chép khi chưa được phép.
Những bài viết liên quan:




Không có đánh giá...